Notes after reading OpenAI Kubernetes related blog posts
This article was last updated on: February 7, 2024 pm
I. Overview
ChatGPT and its company OpenAI have been particularly popular lately: ChatGPT 3, ChatGPT 3.5, New Bing, ChatGPT 4…
With a learning mindset, I visited these days OpenAI’s blog, The above content about AI is indeed interlaced like a mountain, and I can’t understand it at all. 😂
But looking through the process, I was pleasantly surprised to find 2 articles related to the use of Kubernetes:
- January 2018:Scaling Kubernetes to 2,500 nodes (openai.com)
- January 2021:Scaling Kubernetes to 7,500 nodes (openai.com)
This does not touch the old line, learn the next ~
The following are the notes after reading, and also added their own thinking: how to further optimize the monitoring, image pull, and container orchestration related architectures in view of the current situation of OpenAI.
Second, take notes after reading
2.1 Dota 2’s OpenAI is running on Kubernetes

💪💪💪
The Dota2 game image is about 17GB😛
2.2 How OpenAI uses Kubernetes
2.2.1 Purpose
Kubernetes is mainly used in deep learning in OpenAI, mainly using Kubernetes Job.
2.2.2 Reasons for choosing Kubernetes
Kubernetes provides:
- Fast iteration cycle
- Reasonable scalability
- Standard template
2.2.3 Kubernetes cluster scale
- The cluster runs on AZure
- In the 2018 blog post, the cluster node size was more than 2500
- In the 2021 blog post, the cluster node size is more than 7500
2.2.4 Problems encountered in the use of Kubernetes at hyperscale
- etcd
- Kube masters
- Docker image pull
- Internet
- KubeDNS
- ARP cache for the machine
2.2.5 Kubernetes companion tools
- Monitor:
- DataDog (Business Surveillance)
- Prometheus + Grafana
- Log:
- fluentd
- Internet:
- It started with Flannel
- This is followed by the VMSSes CNI plug-in for Azure
2.3 Problems and solutions discovered by Kubernetes hyperscale
2.3.1 Etcd
2.3.1.1 Problem Description
After clustering 500 nodes, kubectl initially uses cards; In addition, DataDog monitoring found that disk write latency soared to hundreds of ms, despite the fact that each machine used a P0,5 SSD with 30,5 IOPS.
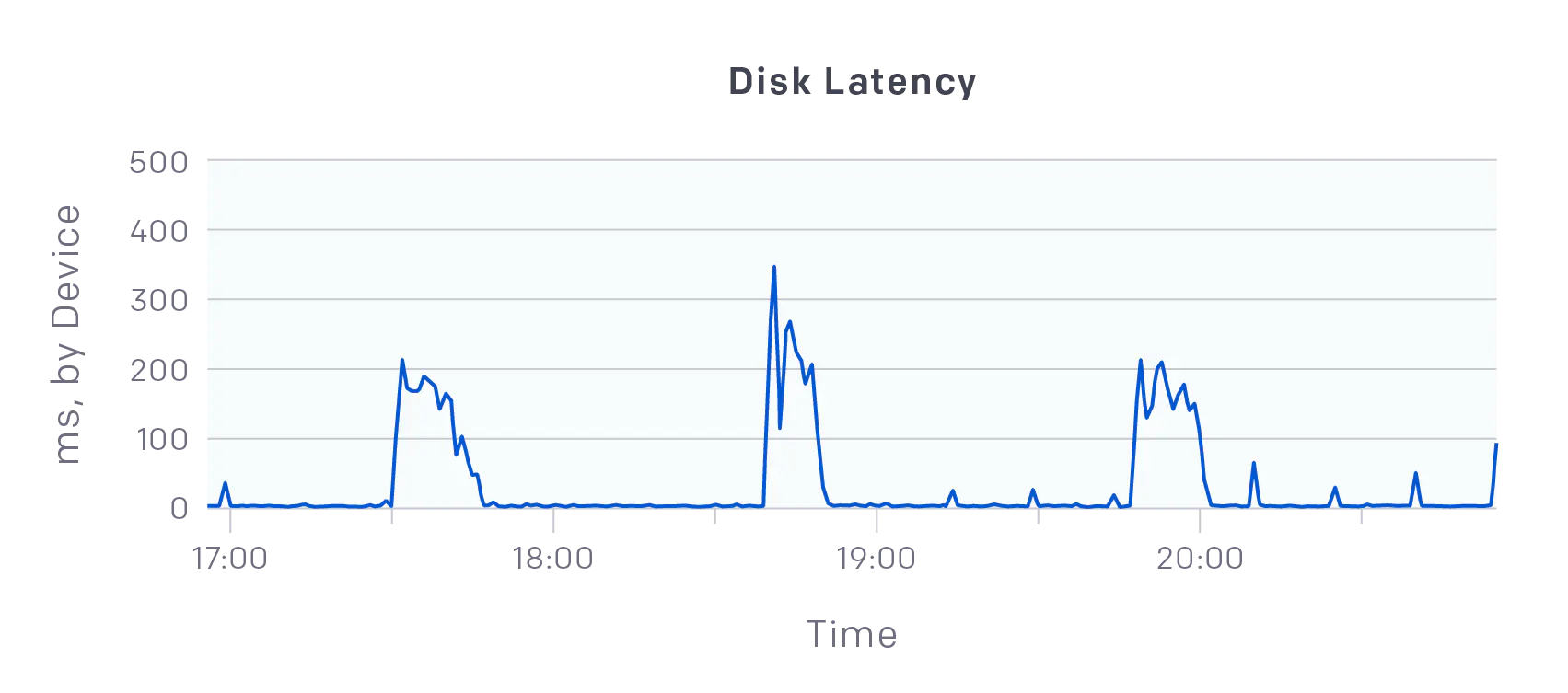
After the solution later, it was added to 1000 nodes and found that the etcd latency became higher again; It was found that kube-apiservers read from etcd at a rate of more than 500MB/s
Another failure after 1,000 nodes was reaching etcd’s hard storage limit (2GB by default), which caused it to stop accepting writes.
2.3.1.2 Solutions
- Move each node’s etcd directory to a local temporary disk, which is an SSD attached directly to the instance, not a network-attached SSD. Switching to a local disk brings write latency to 200us, etcd becomes healthy! (Based on our previous experience with Azure, its network SSD is really not very performant 😂)
- The problem with 1000 nodes is
- Audit logging is enabled
- Prometheus enabled monitoring of APIServer
- This resulted in many slow queries and excessive calls to the LIST API for events
- Root cause: The monitoring process for fluentd and Datadog by default setting is to query the API server from each node in the cluster. “We” simply changed these processes to make their polling less aggressive and the load on the apiserver stabilized again
- Store Kubernetes Events in a separate etcd cluster so that spikes in event creation do not affect the performance of the primary etcd instance. Configure the code snippet as follows
- We use logos
--quota-backend-bytesIncreased the maximum etcd size.
--etcd-servers-overrides=/events#https://0.example.com:2381;https://1.example.com:2381;https://2.example.com:2381
Finally, etcd and APIServer both run on dedicated nodes. Avoid mutual influence.
At 7500 nodes, there are 5 etcd nodes.
2.3.2 API Server
At 7500 nodes, there are 5 API servers, and each API server uses up to 70GB of heap memory.
2.3.3 Docker image pull
2.3.3.1 Problem Description
Dota containers will remain pending for a period of time – but the same is true for other containers.
After resolution, an error is reported:rpc error: code = 2 desc = net/http: request canceled, indicating that the image pull has been canceled due to lack of progress.
Another problem is that OpenAI’s Kubernetes component images are the default slave gcr.io Pulled, however gcr.io It may fail or exceed the quota (the NAT public IP address used by the machine is the same, and it is easy to exceed the quota).
2.3.3.2 Solutions
kubelet There is one --serialize-image-pulls The default is true , indicating that the Dota image pull is blocking all other images.
will --serialize-image-pulls Changed to false; Moved the Docker root to an instance-attached SSD (not a network SSD)
For the second problem, large images take too long to pull and pull, or when there is a large backlog of images that need to be pulled. To solve this problem, we will kubelet --image-pull-progress-deadline The flag is set to 30 minutes and sets the Docker daemon max-concurrent-downloads The option is set to 10. The second option does not speed up the fetch of large images, but allows the image queue to be pulled in parallel.
To solve this gcp.io Failed issues with “we” by using docker image save -o /opt/preloaded_docker_images.tar anddocker image load -i /opt/preloaded_docker_images.tarThese Docker images are pre-installed in the machine images of the Kubernetes worker. To improve performance, we do the same for whitelisting common OpenAI internal images such as Dota images.
2.3.3.3 🤔 The author thinks
Regarding the Docker image pull problems encountered by OpenAI, they are very typical problems encountered by large-scale Kubernetes, but there is actually a better solution: P2P image solutions, typically DragonFly.
DragonFly provides an efficient, stable, and secure file distribution and image acceleration system based on P2P technology, and is the standard solution and best practice in the field of image acceleration in cloud-native architectures. Its biggest advantages are:
- P2P-based file distribution: By leveraging P2P technology for file transfer, it maximizes the bandwidth resources of each peer to improve download efficiency and save a lot of cross-room bandwidth, especially expensive cross-border bandwidth.
- Warm-up: P2P acceleration can pre-warm two types of data, image and file, and users can warm up in console operations or directly call APIs.
2.3.4 Network
Flannel is certainly unsustainable in this hyperscale scenario, and at the beginning OpenAI used a very simple brute force solution (also suitable for their use case): pod configuration uses HostNetwork:
...
hostNetwork: true
...
dnsPolicy: ClusterFirstWithHostNet
This is followed by the VMSSes CNI plug-in that uses Azure instead.
2.3.4.1 🤔 The author thinks
In fact, OpenAI’s rigid need for Kubernetes is: container orchestration, network functions are not just needed, OpenAI can do without Kubernetes CNI. We’ll expand on that later.
2.3.5 ARP caching
Another point that may often be overlooked is the ARP cache issue.
2.3.5.1 Problem Description
One day, an engineer reported that their Redis server nc -v It takes more than 30 seconds to print that the connection has been established. We traced that this issue was caused by the kernel’s ARP stack. A preliminary investigation of Redis pod hosts revealed that something was seriously wrong with the network: communication on any port took several seconds, and DNS names could not be resolved by the local dnsmasq daemon, and the dig simply printed a mysterious failure message:socket.c:1915: internal_send: 127.0.0.1#53: Invalid argument。 The dmesg log is more informative:neighbor table overflow! This means that the ARP cache has run out of space. ARP is used to map network addresses, such as IPv4 addresses, to physical addresses, such as MAC addresses.
2.3.5.2 Solutions
at/etc/sysctl.confIn the setting options:
net.ipv4.neigh.default.gc_thresh1 = 80000
net.ipv4.neigh.default.gc_thresh2 = 90000
net.ipv4.neigh.default.gc_thresh3 = 100000
Tuning these options in a Kubernetes cluster is especially important because each pod has its own IP address, which consumes space for the ARP cache.
2.3.6 Prometheus and Grafana
Due to the large number of acquisitions and queries, the frequency of Prometheus and Grafana OOM is not low.
2.3.6.1 Solutions
- Grafana: It’s essentially a Prometheus high cardinality problem, which I’ve covered before, here:
- Prometheus: WAL replay is an issue after a reboot, and it usually takes hours to replay all WAL logs before Prometheus collects new metrics and service queries.
- use
GOMAXPROCS=24configuration, during WAL replay, Prometheus tries to use all the cores, and for servers with a large number of cores, this scramble kills all performance.
- use
2.3.6.2 🤔 The author thinks
- Recent versions of Prometheus will perform much better, and upgrading to the latest version in time will go a long way in helping with performance issues. For example, high cardinality, large memory, CPU consumption, etc. have been optimized to a certain extent.
- In the case of such a large-scale cluster, Prometheus recommends creating multiple high-end machines with node role monitoring (also attached to local SSDs) for Prometheus to use.
- Or go a step further, opt for other Prometheus-compatible options, such as:VictoriaMetrics (suitable for storage as block storage scenarios) and published by Grafana Labs Mimir (suitable for storage as object storage scenarios).
2.4 OpenAI Kubernetes usage scenarios and recommended alternatives
Here’s a detailed description of OpenAI Kubernetes usage scenarios:
- The main resource type used is Job
- For many workloads in OpenAI, a single pod occupies the entire node
- OpenAI’s current clusters have full bisecting bandwidth and do not consider any rack or network topology
- OpenAI relies less on Kubernetes load balancing, with little HTTPS traffic, no A/B testing, blue/green or canary
- Pods use MPI via SSH to communicate directly with each other on their pod IP addresses (hostNetwork) instead of through the service endpoint
- Service discovery is limited
- There are some PersistentVolumes, but blob storage is much more scalable
- Avoid using overlay networks because it affects network performance
2.4.1 🤔 The author thinks
Read Scaling Kubernetes to 7,500 nodes (openai.com) This article, in fact, will find that OpenAI’s use of Kubernetes is still quite different from ordinary IT companies.
The main use of OpenAI is: KubernetesContainer orchestration, especially right Job of scheduling capabilities.
Other Kubernetes features are used with little or no such as:
- Very little is used to store CSI, mainly blob storage
- Network CNI is used, but pods mainly use hostNetwork
- DNS is not used much
- Service is rarely used, and pods mainly use hostNetwork
- Ingress (i.e. Kubernetes load balancing) is rarely used because Kubernetes clusters are mostly used for experimentation (and may be used more than before with the mass use of ChatGPT)
- Some of Kubernetes’ advanced release strategies, such as A/B testing, are also not required for blue/green or canary
So I personally think (the opinion is for reference only) that Kubernetes is still a bit too complex and redundant for OpenAI.
What OpenAI really needs is a pureContainer orchestrationSolution, especially to Job of scheduling capabilities.
So I think, regardless of user scale, regardless of Kubernetes being the de facto standard in the container orchestration space, HashiCorp Nomad Instead, it is a more appropriate solution. Here are the specific reasons:
- Nomad is an easy-to-use, flexible, and high-performance workload scheduler that deploys hybrid microservices,Batch processing、Containerizationand non-containerized applications.
- GPU support: Nomad provides built-in support for GPU workloads such as machine learning (ML) and artificial intelligence (AI). Nomad uses device plug-ins to automatically detect and utilize resources from hardware devices such as GPUs, FPGAs, and TPUs.
- Proven scalability: Nomad optimistically concurrency increases throughput and reduces latency for workloads. Nomad has been proven to scale to 10K+ node clusters in a live production environment.
- Simplicity: Nomad runs as a single process with zero external dependencies. Operations staff can easily configure, manage, and scale Nomad. Developers can easily define and run applications.
- 2 of Nomad Scheduler: Batch and System Batch, which are very suitable for OpenAI’s use cases.
- Nomad doesn’t come with service discovery and networking features, just does After version 1.3, adds built-in Local Service Discovery (SD), making Consul or other third-party tools unnecessary. Nomad’s service discovery is not intended to replace these tools. Instead, it’s an alternative that makes it easier to test and deploy simpler architectures.

2.5 Scale-out tips
In addition, I was surprised to find that OpenAI’s blog post mentioned Kubernetes scaling tips, which OpenAI called:CPU & GPU balloons.
The author will introduce you in detail here:
2.5.1 The temporal paradox of horizontal scaling
First, OpenAI’s scale-out requirements involve 2 levels:
- Node scaling at the Kubernetes cluster level is implemented through Cluster AutoScaler (here OpenAI uses its own development, and generally each public cloud provides the corresponding Cluster AutoScaler plugin), in order to quickly scale out Node
- Scale-out (HPA) at the pod level, for the rapid number of horizontal pods.
However, in the case of soaring traffic or business volume, the scaling of Node (that is, cloud virtual machines) is not as rapid as that of pods, and it generally takes several minutes to initialize and start, which in turn affects the horizontal scaling of pods, resulting in the inability to respond to soaring business demand in time.
2.5.2 Solution Overview
To do this, the solution is CPU & GPU balloons, as follows:
The time it takes to create a new pod on a new node is determined by four main factors:
- HPA (Horizontal Pod Autoscaler) response time.
- Cluster Autoscaler response time.
- Node configures the time
- Pod creation time
The main time spent here is the time of Node configuration, which mainly depends on the cloud provider.
A new computing resource is in 3 to 5 minutesIt is quite standard to complete the configuration inside.
An estimate of the time required to create a new pod on a new node 7 min Around.
If you need a new Node, how do you adjust autoscaling to reduce the 7-minute zoom time?
Most of the time is spent on Node configurations, and since you can’t change the time the cloud provider provides resources, a workaround is needed:
Namely:Proactively create nodes(overprovisioning) so that they are already configured when you need them.
Always ensure that a standby node is available:
- Create a node and leave it blank (essentially placing a balloon pod to occupy the node).
- If there are pods in an empty node (non-balloon pod), another empty node is created.
Here, you can run a deployment with enough requests to reserve the entire node.
You can think of this pod as a placeholder—it’s designed to reserve space, not use any resources.
Once you’ve created a real pod, you can evict the placeholder and deploy the pod.
How do you achieve this?
2.5.3 Implementation
- A pod with requests
- Pod deployment priority (PodPriorityClass) and preemption
If your node instance is 2 vCPUs and 8GB of memory, the free space of the pod should be 1.73 vCPU and ~5.9GB of memory (OS, kubelet, kubeproxy, etc. need to reserve certain resources) so that the pod monopolizes the node.
Specific resource requirements can be as follows:
1 | |
Then, to ensure that the pod is evicted immediately after the real pod is created, you need to use it Prioritization and preemption。
Pod priority indicates the importance of a pod relative to other pods.
When a pod cannot be scheduled, the scheduler attempts to preempt (evict) a lower priority pod to schedule a suspended (higher priority) pod.
You can use PodPriorityClass to configure pod priority in a cluster:
1 | |
Since the default priority of a pod is 0, and the value of an overprovisioned PriorityClass is -1, when the cluster runs out of space, the pod will be evicted first.
The previous deployment can be adjusted to: (add in spec.) priorityClassName for overprovisioning)
1 | |
When there aren’t enough resources in the cluster, the placeholder pods are preempted and new pods take their place.
Since placeholder pods become unschedulable, it forces Cluster Autoscaler to add more nodes to the cluster.
🎉🎉🎉
III. Summary
This article learned a lot of tuning skills under a hyperscale Kubernetes cluster by studying the Kubernetes-related blog posts in the OpenAI blog.
Here we sort out the performance problems encountered by OpenAI and their solutions, and explain in detail the scaling tips (placeholders 🎈).
At the same time, combined with the author’s experience, I also made some extended thinking:
- In a Kubernetes cluster,
- Metrics monitoring: It is recommended to replace Prometheus with Mimir published by VictoriaMetrics and Grafana Labs
- Image tool: DragonFly is recommended to use P2P and warm-up to alleviate image pull problems
- In a container/batch orchestration scheduling solution, try choosing HashiCorp’s Nomad instead of Kubernetes.
Above.
Reference documentation
- Scaling Kubernetes to 2,500 nodes (openai.com)
- Scaling Kubernetes to 7,500 nodes (openai.com)
- Prometheus Performance Tuning - What is the High Cardinality Problem and How to Fix It? - Dongfeng Weiming Technology Blog (e-whisper.com)
- Several architectures for large-scale IoT edge container cluster management -2-HashiCorp Solution Nomad - Dongfeng Weiming Technology Blog (e-whisper.com)
- Architecting Kubernetes clusters — choosing the best autoscaling strategy (learnk8s.io)
- Grafana Series Part I: Grafana-based Full-Stack Observability Demo (including Mimir) - Dongfeng Weiming Technology Blog (e-whisper.com)