Minio Architecture Introduction
This article was last updated on: July 24, 2024 am
Brief introduction
Minio is a go written based on the Apache License v2.0 open source protocol object storage system, designed for massive data storage, artificial intelligence, big data analysis, it is fully compatible with Amazon S3 interface, very suitable for storing large capacity of unstructured data from tens of kb to a maximum of 5T. It is a small and beautiful open source distributed storage software.
peculiarity
Simple and reliable: Minio adopts a simple and reliable cluster solution, abandons complex large-scale cluster scheduling management, reduces risk and performance bottlenecks, and focuses on the core functions of the product to create high-availability clusters, flexible expansion capabilities, and superior performance. Establish a large number of small-sized and easy-to-manage clusters, and support the aggregation of multiple clusters into a super large resource pool across data centers, rather than directly adopting large-scale, uniformly managed distributed clusters.
Functionally complete: Minio supports cloud native and can be well connected with Kubernetes, Docker, and Swarm orchestration systems to achieve flexible deployment. And the deployment is simple, only one executable, few parameters, one command can start a Minio system. Minio adopts a metadata-free database design for high performance, avoiding the metabase becoming a performance bottleneck for the entire system, and limiting failures to a single cluster, so that no other clusters are involved. Minio is also fully compatible with the S3 interface, so it can also be used as a gateway to provide S3 access to the outside world. Use both Minio Erasure code and checksum to prevent hardware failures. Even if you lose more than half of your hard drive, you can still recover from it. (N/2)-1 node failure is also allowed in the distribution.
Architecture
Decentralized architecture
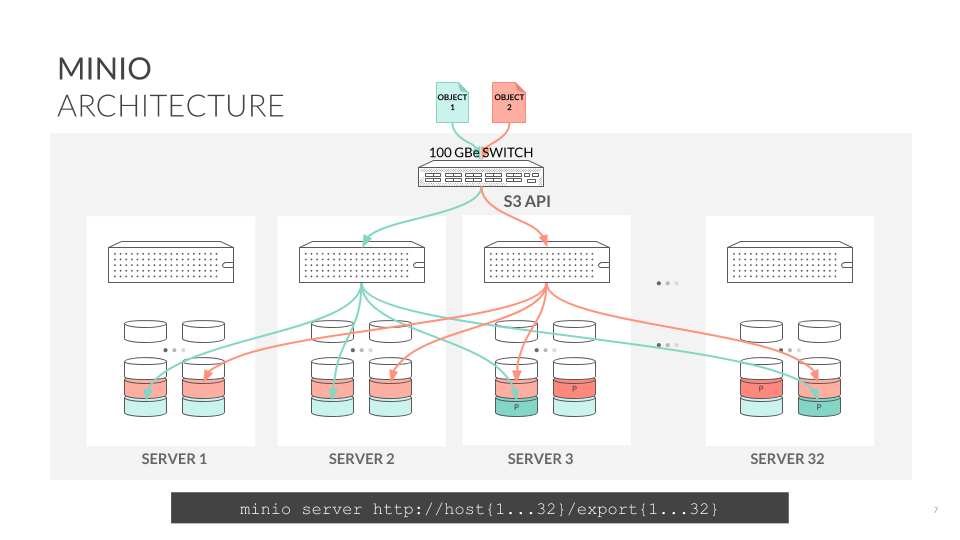
Minio adopts a decentralized shared-nothing architecture, where object data is scattered and stored on multiple hard disks on different nodes, providing unified namespace access and load balancing between servers through load balancing or DNS rounding

Unified namespace
Minio has two cluster deployment methods, one is the common local distributed cluster deployment and the other is the consortium mode deployment. Local distributed cluster deployment deploys Minio services on multiple local server nodes, forms them into a single distributed storage cluster, and provides a unified namespace and annotated S3 provider. Consortium deployment logically forms a unified namespace for multiple local Minio clusters to achieve near-wireless expansion and massive data scale management, and these clusters can be located locally or in data centers distributed in different regions.
Distributed lock management
Similar to distributed databases, Minio suffers from data consistency issues: while one client reads an object, another client may be modifying or deleting the object. To avoid inconsistencies. Minio specifically designed and implemented the dsync distributed lock manager to control data consistency.
- A lock request from any one node is broadcast to all online nodes in the cluster
- If consent is received from N/2+1 nodes, the acquisition is successful
- There is no master node, each node is peered to each other, and the stale lock detection mechanism is used between nodes to determine the status of nodes and the lock status
- Due to the simple design, it is relatively rough. It has certain defects, and supports up to 32 nodes. Scenarios where lock loss cannot be avoided. However, the available needs are basically met.
| EC2 Instance Type | Nodes | Locks/server/sec | Total Locks/sec | CPU Usage |
|---|---|---|---|---|
| c3.8xlarge(32 vCPU) | 8 | (min=2601, max=2898) | 21996 | 10% |
| c3.8xlarge(32 vCPU) | 8 | (min=4756, max=5227) | 39932 | 20% |
| c3.8xlarge(32 vCPU) | 8 | (min=7979, max=8517) | 65984 | 40% |
| c3.8xlarge(32 vCPU) | 8 | (min=9267, max=9469) | 74944 | 50% |
data structure
The Minio object storage system organizes storage resources into tenant-bucket-object forms
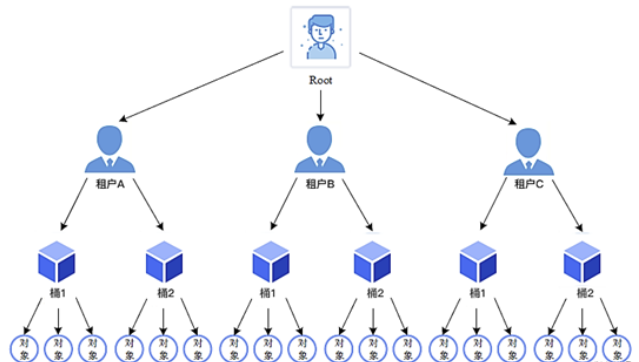
- object: Similar to the table xiang table entry in the hash table, the name is a keyword, and the content is equivalent to a value
- bucket: is a logical abstraction of several objects, a container for objects
- tenant: Used to isolate storage resources. Buckets and storage objects can be created under the tenant
- user: An account created in the tenant to access different buckets. You can use the mc command provided by minio to set the permissions for different users to access each bucket
Uniform Domain Name Access
After the Minio cluster extension adds a new cluster or bucket, the client program of the object storage needs to access the data object through the unified domain name/URL, which involves etcd and CoreDns

Storage mechanism
Minio uses erasure code and checksum to protect data from hardware failures and silent data corruption. Even if you lose half of the number (N/2) of the hard drive, you can still recover your data.
Erasure coding is a mathematical algorithm for recovering lost and damaged data, and the current application of erasure coding technology in distributed storage systems is divided into three categories, array erasure coding (Array code: RAID5, RAID6, etc.), RS (Reed-solomon) Reed-Solomon class erasure coding and LDPC (Low Density Parity Check Code) low-density parity test erasure coding. ErasureCode is a coding technology that can add M copies of the original data, and restore the original data through any N points of data in N+M copies. That is, if any data loss is less than or equal to M parts, it can still be restored through the remaining data.
Minio uses Reed-solomon code to split objects into N/2 data and N/2 parity test fast, which means that if it is 12 disks, an object will be divided into 6 data blocks, 6 parity test fast, can lose any 6 disks (regardless of the stored data fast or parity test fast), so that it can recover from the data in the remaining disks.
In an N-node distributed minio, as long as there are N/2 nodes online, your data is safe. However, at least N/2+1 nodes are required for write operations.
After uploading a file to Minio, the information on the disk is as follows:

where xl.json is the metadata file for this object. part.1 is the first data shard for this object. (Each node in the distribution will have these two files, namely data block and parity fast) When reading data, Minio will perform HighwayHash encoding on the encoding fast, and then verify it to ensure the correctness of each encoding. Based on the Erasure Code and Bit Rot Protection’s HighwayHash, Minio’s data reliability is high.
Lambda compute and continuous backup
Minio supports lambda compute notification mechanism, that is, objects in the bucket support event notification mechanism. The supported event types are: object upload, object download, object deletion, and object replication. The current support event acceptance systems are: redis, NATS, AMQP, Kafka, mysql, elasticsearch, etc.
The object notification mechanism enhances the extensibility of Minio, allowing users to implement certain functions that are not implemented by Minio through self-development. For example, metadata retrieval, user’s business-related calculations, etc. At the same time, fast and efficient incremental backups can be made through this mechanism.
Object Storage Gateway
In addition to being a storage system service, Minio can also be used as a gateway, and the backend can be used with distributed file systems such as NAS systems and HDFS systems, or third-party storage systems such as S3 and OSS. With the Minio gateway, S3-compatible APIs can be added to these back-end systems for easy management and portability, because S3 APIs are already a de facto label in the object storage world.

Users request storage resources through the unified S3 API, and route each request to the corresponding ObjectLayer through the S3 API Router, and each ObjectLayer corresponds to all APIs that implement object operations on each storage system. For example, after GCS (Google cloud storage) implements the ObjectLayer interface, its operation on back-end storage is implemented through the GCS SDK. When the terminal obtains the bucket list through the S3 API, the final implementation accesses the GCS service through the GCS SDK to obtain the bucket list, and then packages the S3 standard structure to return it to the terminal.