The network is limited, and it is necessary to ensure that the network is smooth.
deploy
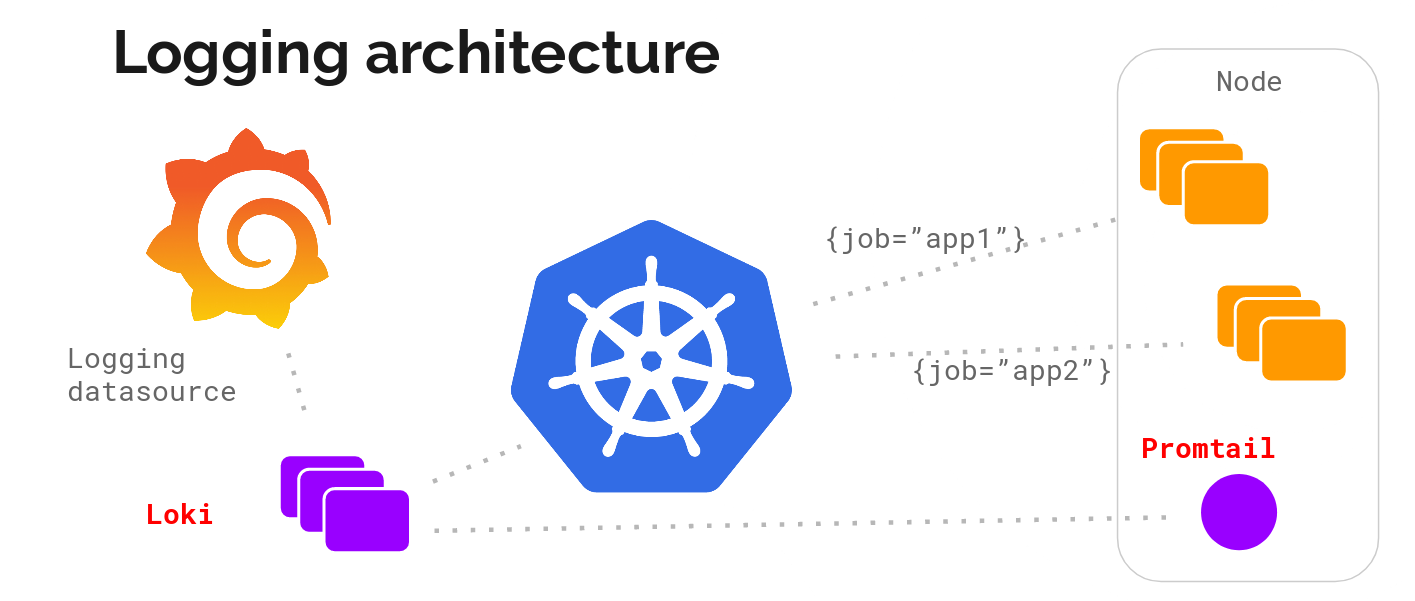
Architecture
Promtail (collection) + Loki (storage and processing) + Grafana (display)
Promtail
Enable Prometheus Operator Service Monitor for monitoring
increaseexternal_labels - clusterto identify which K8S cluster it is;
pipeline_stages Changed to crito process the cri log (because my cluster uses a container runtime of CRI, and Loki Helm is configured by default.) docker)
Increase to the pair systemd-journal Log collection:
grafana: enabled:true adminUser:caseycui adminPassword:changit! ## Sidecars that collect the configmaps with specified label and stores the included files them into the respective folders ## Requires at least Grafana 5 to work and can't be used together with parameters dashboardProviders, datasources and dashboards sidecar: image: repository:quay.io/kiwigrid/k8s-sidecar tag:1.15.6 sha:'' dashboards: enabled:true SCProvider:true label:grafana_dashboard datasources: enabled:true # label that the configmaps with datasources are marked with label:grafana_datasource plugins: enabled:true # label that the configmaps with plugins are marked with label:grafana_plugin notifiers: enabled:true # label that the configmaps with notifiers are marked with label:grafana_notifier image: tag:8.3.5 persistence: enabled:true size:2Gi storageClassName:local-path serviceMonitor: enabled:true imageRenderer: enabled:disable
filebeat: enabled:false
logstash: enabled:false
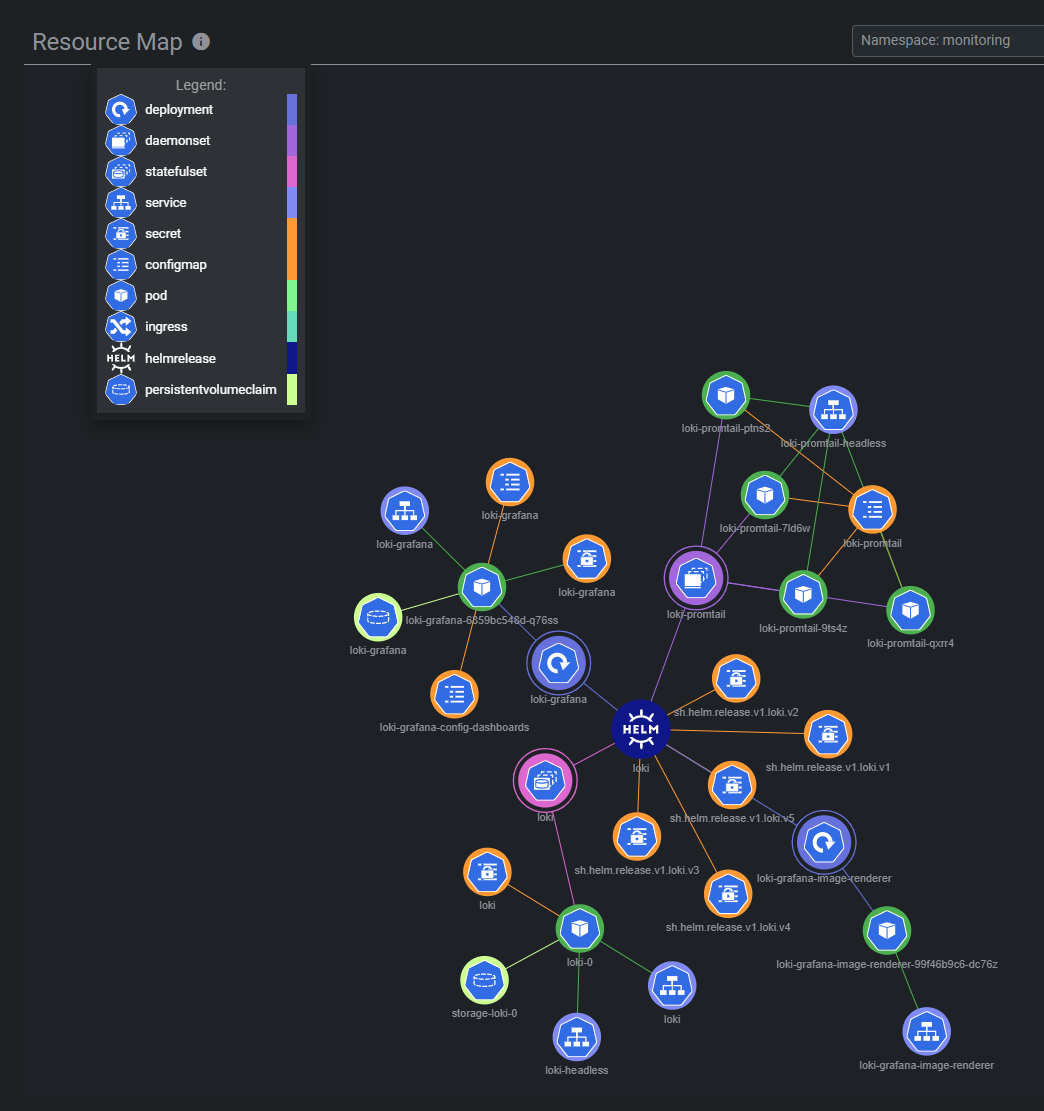
The installed resource topology is as follows:
Day 2 Configuration (On-Demand)
Grafana adds Dashboards
Under the same NS, create the following ConfigMap: (Just type.)grafana_dashboard This label will be automatically imported by Grafana’s sidecar.)