Reading Notes - Large-scale Distributed Storage Systems - Principle Analysis and Architecture Practice - 7
This article was last updated on: July 24, 2024 am
7 Distributed databases
Relational databases were designed without foreseeing the IT industry evolving so fast.Always assume that the system is running on a stand-alone machineThis closed system.
7.1 Database Middle Tier
Most common practice: The application layer splits the data into multiple according to the rulesSharding, distributed across multiple database nodes, andIntroduce an intermediate tierto mask the back-end database split details of the application.
7.1.1 Architecture
Take MySQL Sharding as an example:
- Middle-tier dbproxy cluster: Parses client SQL requests and forwards them to the back-end database. Specifically: parse MySQL protocol, perform SQL routing, SQL filtering, read/write splitting, result merging, sorting, and grouping. Consists of multiple stateless dbproxy processes, and there is no single point of occurrence. In addition, LVS can be introduced between the client and the middle tier to load balance client requests. It is important to note that client requests require an additional layer of communication overhead, so it is common practice to configure the list of middle-tier servers directly on the client, and the client handles requests load balancing and middle-tier server failures.
- Database group: Each dbgroup consists of N database machines, one of which is Master and the other is Slave.The master is responsible for all write transactions and strongly consistent read transactions, and replicates the operation to the standby in the form of binlog, which can support read transactions with a certain delay.
- Metadata Server: Responsible for maintaining dbgroup split rules and using dbgroup mastering. dbproxy obtains the splitting rules through the metadata server to determine the execution plan for the SQL statement. In addition, if the dbgroup master fails, the master needs to be selected through the metadata server. The metadata server itself also requires multiple replicas to implement HA, and the common way is to use Zookeeper implementations.
- Resident process agents: used to implement monitoring, single point switching, installing, uninstalling programs, etc.
MySQL client library: Applications interact with the system through MySQL’s native client and support JDBC.
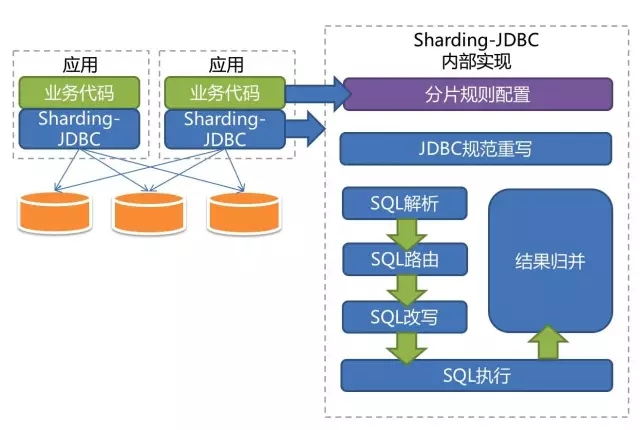
Suppose the database is partitioned by user hash, and the data of the same user is distributed across a database group. If the SQL request involves only the same user (which is true for most applications), then the middle tier forwards the request to the appropriate database group, waits for the result to be returned, and returns the result to the client; If the SQL request involves multiple users, the middle tier needs to forward it to multiple database groups, wait for the results to be returned, and perform operations such as merging, grouping, and sorting the results back to the client. Since the protocol of the middle tier is compatible with MySQL, the client does not feel the difference between accessing a single MySQL machine.
7.1.2 Expansion
MySQL Sharding clusters are generally hashed partitioned by user ID, and there are two problems:
- Insufficient cluster capacity: doubling the scaling solution, from 2 -> 4 -> 8 …
- The data volume of a single user is too large: Large users are regularly counted at the application layer, and the data of these users is split into multiple dbgroups according to the data volume. Of course, maintaining this information regularly is a big price to pay for the application layer.
Common expansion methods: (Assume 2 dbgroups, the first dbgroup master is A0, the standby is A1, the second dbgroup master is B0, and the standby is B1.) According to the user ID hash modulus 2, users with a result of 0 are distributed in the first dbgroup, and users with a result of 1 are distributed in the second dbgroup)
- Wait for the data of A0 and B0 to sync to their standby servers, that is, A1 and B1
- Stop the write service, wait for the primary/standby to fully synchronize, and then dissolve the primary/standby relationship between A0 and A1 and B0 and B1
- Modify the mapping rules of the middle tier to map the user data with a hash modulo 4 equals 2 to A1, and the user data with a hash modulo 4 equals 3 to B1
- When the write service is enabled, data with a user ID hash value modulo of 4 equal to 0/1/2/3 will be written to A0/A1/B0/B1, respectively. This equates to half of the data being migrated from A0 and B0 to A1 and B1, respectively.
- Add a standby to A0, A1, B0, and B1 respectively
Eventually, the cluster changes from 2 dbgroups to 4 dbgroups. It can be seen that the scaling process needs to stop the service for a short time, and if the server failure occurs again during the scaling process, it will make the scaling very complicated and difficult to fully automate.
7.1.3 Discussion
It is common for large Internet companies to introduce a middle layer of databases to make back-end shards and tables transparent to applications. This approach is simple to implement and app-friendly, but there are some problems:
- Database replication: Only asynchronous replication may be supported, and the pressure on the primary database may cause a large delay, so the primary/standby switchover may lose part of the update transactions, which requires manual intervention
- Scaling problem: Scaling involves data repartitioning, and the whole process is complex and error-prone
- Dynamic data migration issues: Difficult to automate.
7.2 Microsoft SQL Azure
7.3 Google Spanner
Google’sGlobally-Distributed Database。 Scalability is global, scaling to hundreds of data centers, millions of servers, and hundreds of millions of rows of records. It can also passSynchronous replication and multi-versioningto meet external consistency and support cross-central transactions.
7.3.1 Data Model
For a typical album application, to store users and albums, perform the following table creation statement:
1 | |
Spanner tables are hierarchical, and the lowest table is a directory table, which can be used when other tables are created INTERLEAVE IN PARENT to represent hierarchical relationships.
When actually storing, Spanner will put together data from the same directory, and as long as the directory is not too large, each copy of the same directory will be assigned to the same machine. Therefore, read and write transactions against the same directory will not involve cross-machine operations in most cases.
7.3.2 Architecture
Spanner is built on top of Google’s next-generation distributed file system, Colossus. Colossus is a continuation of GFS, and the main improvement over GFS is ColossusReal-time and support for a large number of small files
Spanner concept:
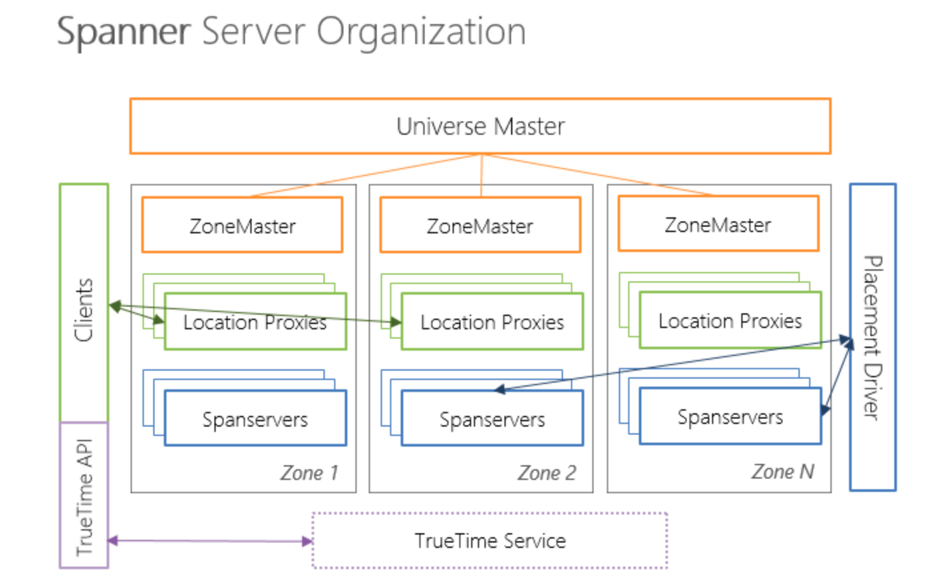
- Universe: An instance of a Spanner deployment is called a universe. There are currently 3 in the world, one development, one test, and one online. Universe supports multi-data center deployment, and multiple businesses can share the same universe
- Zones: Each zone belongs to a data center, and a data center may have multiple zones. In general, network communication within zones is less expensive, while communication between zones is expensive. (The zone concept is similar to region)
Spanner consists of the following components:
- Universe Master: Monitor zone-level status information in this universe.
- Placement Driver: Provides cross-zone data migration capabilities.
- Location Proxy: Provides a location information service that obtains data. It is needed by the client to know which Spanserver the data is being served.
- Spanserver: Provides storage services, functionally equivalent to Tablet Server in the Bigtable system
Each Spanserver serves multiple child tables, which in turn contain multiple directories. When a client sends a read and write request to Spanner, it first finds the Spanserver where the directory is located, and then reads and writes data from the Spanserver.
7.3.3 Replication and Consistency
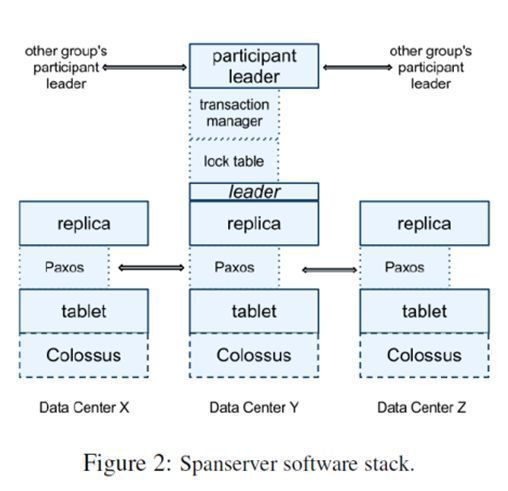
Each data center runs a set of Colossus, with 100 - 1000 child tables per machine, each of which deploys multiple replicas in multiple data centers. To synchronize the system’s operational logs, a Paxos state machine runs on each child table. The Paxos protocol selects a replica as the primary replica, and the default lifetime of the primary replica is 10s. Under normal circumstances, this primary replica will elect itself as the primary replica again when it is about to expire; If the primary replica goes down, the other replicas are elected as the new primary replicas after 10s through the Paxos protocol.
Consistency across multiple replicas across data centers is achieved through the Paxos protocol. In addition, the Spanserver where each primary replica resides will also implement a lock table for concurrency control, and read and write transactions need to avoid interfering with multiple transactions through lock tables when operating directories on a child table.
In addition to the lock table, each primary replica has a transaction manager. If the transaction is in a Paxos group, the transaction manager can be bypassed. But once a transaction spans multiple Paxos groups, the transaction manager is required to coordinate it.
Lock tables implement stand-alone transactions within a single Paxos group, and transaction managers implement distributed transactions across multiple Paxos groups. To implement distributed transactions, a two-phase commit protocol needs to be implemented. The master replica of one Paxos group becomes the coordinator in the two-phase commit agreement, and the master replica of the other Paxos groups is the participant.
7.3.4 TrueTime
Each transaction is assigned a globally unique transaction ID. Spanner passed Global clock synchronization mechanism Truetime Implement.
Truetime returns the timestamp t and error e. The real system e averages only 4 ms.
The basis of the Truetime API implementation is GPS and atomic clocks.
Each data center needs to deploy some master clock servers (Master), and a slave process on other machines to synchronize clock information from the master clock server. Some master clock servers use GPS, and some use atomic clocks.
7.3.5 Concurrency Control
The following transactions are supported:
- Read and write transactions
- Read-only transactions
- The snapshot is read, and the client provides the timestamp
- Snapshot read, the client provides the time range
Consider TrueTime, to guarantee transaction order, transaction T1 is committed after t1 + e, and transaction T2 is committed after t2 + e. This means that the latency for each write transaction is at least 2e.