Reading Notes: "Large-scale Distributed Storage Systems: Principles and Architecture in Action": VI
This article was last updated on: July 24, 2024 am
6 Distributed table system
Google Bigtable is the ancestor of the distributed table system, which adopts a two-tier structure, and the bottom layer uses GFS as the persistent storage layer. The GFS + Bigtable two-tier architecture is a landmark architecture.
6.1 Google Bigtable
Bigtable is a distributed table system based on GFS and Chubby developed by Google.
Massive amounts of structured and semi-structured data, including web indexes and satellite image data, are stored in Bigtable.
Bigtable is a distributed multidimensional mapping table:
(row:string, column:string, timestamp:int64) -> string
Bigtable organizes multiple columns into column families, so that the column name consists of 2 parts: (column family, qualifier). A column family is the basic unit of access control in a Bigtable.
6.1.1 Architecture
Bigtable is built on top of GFS to add a distributed index layer to the file system. In addition, Bigtable relies on Google’s Chubby (distributed lock service) for server election and global information maintenance.
Bigtable divides large tables into tablets between 100 and 200 MB in size, each corresponding to a continuous range of data. Bigtable consists of 3 main parts:
- Client Library: The interface of the Bigtable to the application. However, the data content is transferred directly between the client and the child table server.
- A master server: manages all sub-table servers, including assigning sub-tables to sub-table servers, guiding sub-table servers to merge sub-tables, accepting sub-table split messages from sub-table servers, monitoring sub-table servers, load balancing between sub-table servers, and implementing failure recovery of sub-table servers.
- Multiple sub-table servers (tablet servers): realize the loading, unloading, reading and writing of table content, merging and splitting of child tables. The operation log and the sstable data on each child table are stored in the underlying GFS.
Bigtable relies on the Chubby lock service to do the following:
- Select and ensure that there is only one master server at a time;
- Stores Bigtable system boot information;
- It is used to cooperate with the master server to discover the joining and offline of sub-table servers;
- Obtain schema information and access control information for Bigtable tables.
Chubby is a distributed lock service with Paxos at the core of the underlying algorithm. Typical deployments are: three centers and five replicas in two places, two replicas in two data centers in the same city, and one copy in remote data centers, and the failure of any data center as a whole will not affect normal services.
Bigtable contains three types of tables:
- User Table: Stores the actual data of users
- Metadata table (Meta Table): Stores metadata of user tables, such as sub-table location information, SSTable and operation log file numbers, log playback points, etc
- Root Table: Stores the metadata of the metadata table. The metadata of the root table, that is, the location information of the root table, also known as the Bigtable boot information, is stored in the Chubby system. The client, the master server, and the child table server all need to rely on the Chubby service during execution, and if Chubby fails, Bigtable is unavailable as a whole.
6.1.2 Data Distribution
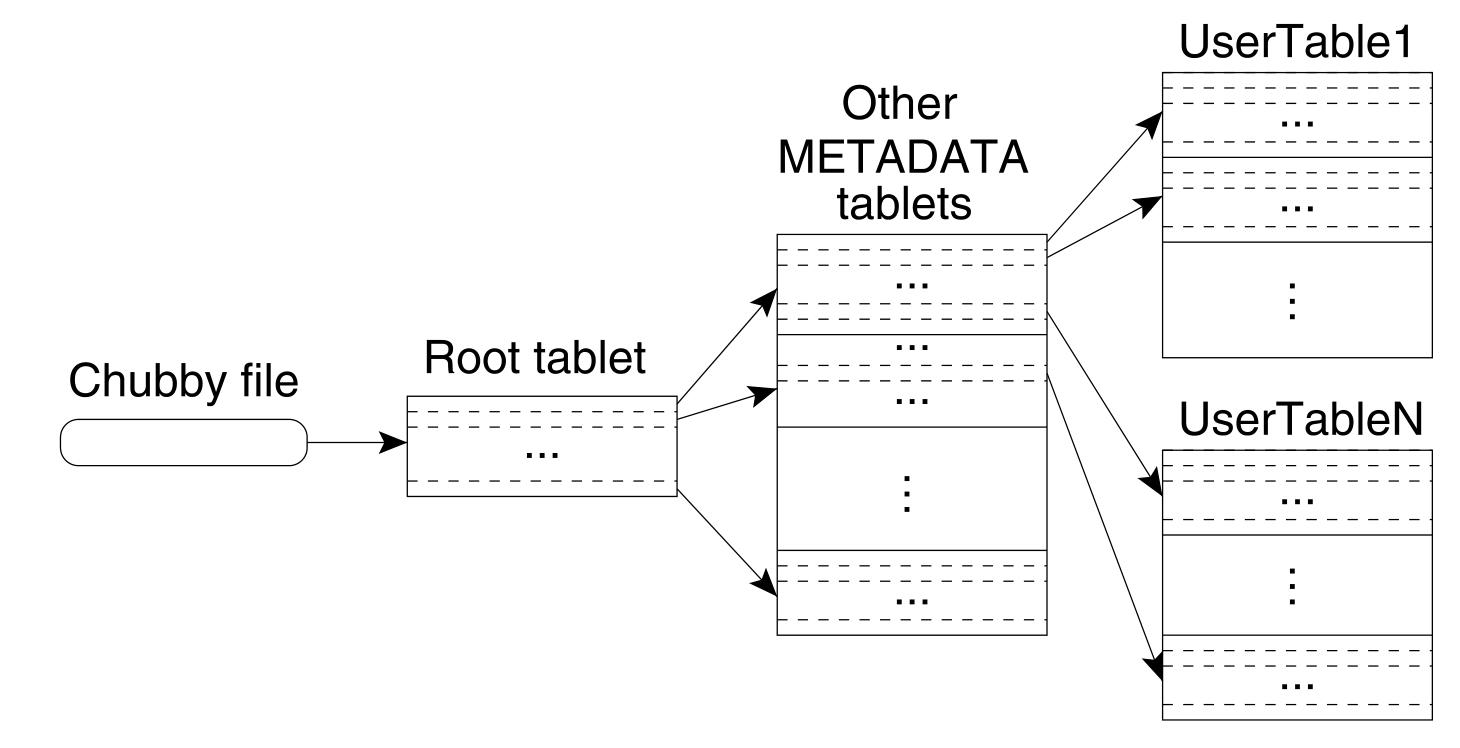
Assuming that the average subtable is 128MB and the meta information of each subtable is 1KB, the amount of data that L1 metadata can support is 128MB * (128MB/1KB) = 16TB, the amount of data that can be supported by two-level metadata is 16TB*(128MB/1KB)=2048 PB, to meet the data volume needs of almost any business.
The client uses cache and prefetch techniques.
6.1.3 Replication and Consistency
The Bigtable system guarantees strong consistency, and the same subtable can only be served by one TabletServer at a time. Implemented through Chubby mutexes.
There are two types of data that Bigtable writes to GFS:
- Operational logs.
- Each child table contains SSTable data.
6.1.4 Fault Tolerance
6.1.5 Load balancing
A child table is the base unit of Bigtable load balancing.
Load balancing: Migration of child tables.
6.1.6 Splitting and Merging
6.1.7 Stand-alone storage
Bigtable uses the Merge-dump engine. Both random and sequential reads require only one access to the disk.
6.1.8 Garbage Collection
Mark-and-sweep
6.1.9 Discussion
GFS + Bigtable balances system consistency and availability.
The underlying GFS is weak in consistency, and the availability and performance are good; The upper-level table system Bigtable makes the overall external performance of strong consistency through multi-level distributed indexing.
The biggest advantage of Bigtable is that it is linear and scalable.
The Bigtable architecture faces some problems:
- Single copy service. The Bigtable architecture is suitable for offline or semi-online applications.
- SSD use.
- The complexity of the architecture makes it difficult to locate bugs
6.2 Google Megastore
Friendly database function support on top of the Bigtable system for enhanced ease of use. Megastore plugs into traditional relational databases and storage technology between NoSQL.
6.2.1 System Architecture
6.2.2 Entity Groups
6.2.3 Concurrency Control
6.2.4 Replication
6.2.5 Indexing
- Local indexes
- Global indexes
- STORING clause
- Repeatable indexes
6.2.6 Coordinators
6.2.7 Read Process
6.2.8 Write Process
6.2.9 Discussion
Two goals for distributed storage systems:
- scalability, with the ultimate goal of linear scaling;
- function, the ultimate goal is to support full-featured SQL.