This article was last updated on: July 24, 2024 am
Previous article
IoT edge clusters are implemented based on alarm notifications from Kubernetes Events
target
Alarm recovery notification - This cannot be achieved after evaluation
Cause: Alarms and recovery are separate completely unrelated events, alarms are Warning level, recovery is Normal level, to turn on recovery, will lead to all Normal Events are sent, and this amount is terrifying; And, unless you are particularly experienced and patient, you can’t tell which one Normal The corresponding is the recovery of alarms.
Continuous alerting without recovery – the ability to come by default, no additional configuration required.
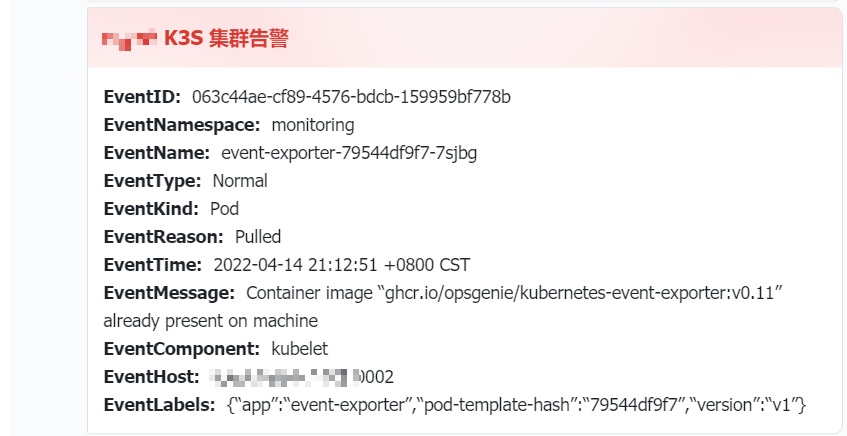
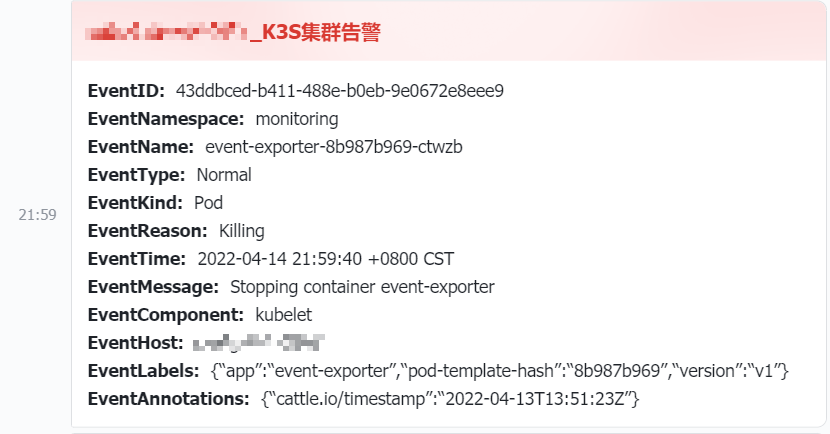
The alarm content displays the resource name, such as node and pod names
Fencing specific nodes and workloads can be set up and can be adjusted dynamically
For example, clusters001node in worker-1Do planned maintenance, stop monitoring during the period, and restart monitoring after the maintenance is completed.
disposition
The alarm content displays the resource name
Typical types of events:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 apiVersion: v1 count: 101557 eventTime: null firstTimestamp: "2022-04-08T03:50:47Z" involvedObject: apiVersion: v1 fieldPath: spec.containers{prometheus} kind: Pod name: prometheus-rancher-monitoring-prometheus-0 namespace: cattle-monitoring-system kind: Event lastTimestamp: "2022-04-14T11:39:19Z" message: 'Readiness probe failed: Get "http://10.42.0.87:9090/-/ready": context deadline exceeded (Client.Timeout exceeded while awaiting headers)' metadata: creationTimestamp: "2022-04-08T03:51:17Z" name: prometheus-rancher-monitoring-prometheus-0.16e3cf53f0793344 namespace: cattle-monitoring-system reason: Unhealthy reportingComponent: "" reportingInstance: "" source: component: kubelet host: master-1 type: Warning
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 apiVersion: v1 count: 116 eventTime: null firstTimestamp: "2022-04-13T02:43:26Z" involvedObject: apiVersion: v1 fieldPath: spec.containers{grafana} kind: Pod name: rancher-monitoring-grafana-57777cc795-2b2x5 namespace: cattle-monitoring-system kind: Event lastTimestamp: "2022-04-14T11:18:56Z" message: 'Readiness probe failed: Get "http://10.42.0.90:3000/api/health": context deadline exceeded (Client.Timeout exceeded while awaiting headers)' metadata: creationTimestamp: "2022-04-14T11:18:57Z" name: rancher-monitoring-grafana-57777cc795-2b2x5.16e5548dd2523a13 namespace: cattle-monitoring-system reason: Unhealthy reportingComponent: "" reportingInstance: "" source: component: kubelet host: master-1 type: Warning
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 apiVersion: v1 count: 20958 eventTime: null firstTimestamp: "2022-04-11T10:34:51Z" involvedObject: apiVersion: v1 fieldPath: spec.containers{lb-port-1883} kind: Pod name: svclb-emqx-dt22t namespace: emqx kind: Event lastTimestamp: "2022-04-14T11:39:48Z" message: Back-off restarting failed container metadata: creationTimestamp: "2022-04-11T10:34:51Z" name: svclb-emqx-dt22t.16e4d11e2b9efd27 namespace: emqx reason: BackOff reportingComponent: "" reportingInstance: "" source: component: kubelet host: worker-1 type: Warning
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 apiVersion: v1 count: 21069 eventTime: null firstTimestamp: "2022-04-11T10:34:48Z" involvedObject: apiVersion: v1 fieldPath: spec.containers{lb-port-80} kind: Pod name: svclb-traefik-r5p8t namespace: kube-system kind: Event lastTimestamp: "2022-04-14T11:44:59Z" message: Back-off restarting failed container metadata: creationTimestamp: "2022-04-11T10:34:48Z" name: svclb-traefik-r5p8t.16e4d11daf0b79ce namespace: kube-system reason: BackOff reportingComponent: "" reportingInstance: "" source: component: kubelet host: worker-1 type: Warning
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 { "metadata" : { "name" : "event-exporter-79544df9f7-xj4t5.16e5c540dc32614f" , "namespace" : "monitoring" , "uid" : "baf2f642-2383-4e22-87e0-456b6c3eaf4e" , "resourceVersion" : "14043444" , "creationTimestamp" : "2022-04-14T13:08:40Z" } , "reason" : "Pulled" , "message" : "Container image \"ghcr.io/opsgenie/kubernetes-event-exporter:v0.11\" already present on machine" , "source" : { "component" : "kubelet" , "host" : "worker-2" } , "firstTimestamp" : "2022-04-14T13:08:40Z" , "lastTimestamp" : "2022-04-14T13:08:40Z" , "count" : 1 , "type" : "Normal" , "eventTime" : null , "reportingComponent" : "" , "reportingInstance" : "" , "involvedObject" : { "kind" : "Pod" , "namespace" : "monitoring" , "name" : "event-exporter-79544df9f7-xj4t5" , "uid" : "b77d3e13-fa9e-484b-8a5a-d1afc9edec75" , "apiVersion" : "v1" , "resourceVersion" : "14043435" , "fieldPath" : "spec.containers{event-exporter}" , "labels" : { "app" : "event-exporter" , "pod-template-hash" : "79544df9f7" , "version" : "v1" } } }
We can add more fields to the alarm information, including:
Node: {{ Source.Host }}
Pod: {{ .InvolvedObject.Name }}
In summary, modifiedevent-exporter-cfg yaml is as follows:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 apiVersion: v1 kind: ConfigMap metadata: name: event-exporter-cfg namespace: monitoring resourceVersion: '5779968' data: config.yaml: | logLevel: error logFormat: json route: routes: - match: - receiver: "dump" - drop: - type: "Normal" match: - receiver: "feishu" receivers: - name: "dump" stdout: {} - name: "feishu" webhook: endpoint: "https://open.feishu.cn/open-apis/bot/v2/hook/..." headers: Content-Type: application/json layout: msg_type: interactive card: config: wide_screen_mode: true enable_forward: true header: title: IoT edge cluster Alarm notification implementation based on Kubernetes Events (2): Further configuration content: xxx测试K3S集群告警 template: red elements: - tag: div text: tag: lark_md content: "**EventID:** {{ .UID }}\n**EventNamespace:** {{ .InvolvedObject.Namespace }}\n**EventName:** {{ .InvolvedObject.Name }}\n**EventType:** {{ .Type }}\n**EventKind:** {{ .InvolvedObject.Kind }}\n**EventReason:** {{ .Reason }}\n**EventTime:** {{ .LastTimestamp }}\n**EventMessage:** {{ .Message }}\n**EventComponent:** {{ .Source.Component }}\n**EventHost:** {{ .Source.Host }}\n**EventLabels:** {{ toJson .InvolvedObject.Labels}}\n**EventAnnotations:** {{ toJson .InvolvedObject.Annotations}}"
Mask specific nodes and workloads
For example, clusters001node in worker-1Do planned maintenance, stop monitoring during the period, and restart monitoring after the maintenance is completed.
Continue modifyingevent-exporter-cfg yaml is as follows:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 apiVersion: v1 kind: ConfigMap metadata: name: event-exporter-cfg namespace: monitoring data: config.yaml: | logLevel: error logFormat: json route: routes: - match: - receiver: "dump" - drop: - type: "Normal" - source: host: "worker-1" - namespace: "cattle-monitoring-system" - name: "*emqx*" - kind: "Pod|Deployment|ReplicaSet" - labels: version: "dev" match: - receiver: "feishu" receivers: - name: "dump" stdout: {} - name: "feishu" webhook: endpoint: "https://open.feishu.cn/open-apis/bot/v2/hook/..." headers: Content-Type: application/json layout: msg_type: interactive card: config: wide_screen_mode: true enable_forward: true header: title: IoT edge cluster Alarm notification implementation based on Kubernetes Events (2): Further configuration content: xxx测试K3S集群告警 template: red elements: - tag: div text: tag: lark_md content: "**EventID:** {{ .UID }}\n**EventNamespace:** {{ .InvolvedObject.Namespace }}\n**EventName:** {{ .InvolvedObject.Name }}\n**EventType:** {{ .Type }}\n**EventKind:** {{ .InvolvedObject.Kind }}\n**EventReason:** {{ .Reason }}\n**EventTime:** {{ .LastTimestamp }}\n**EventMessage:** {{ .Message }}\n**EventComponent:** {{ .Source.Component }}\n**EventHost:** {{ .Source.Host }}\n**EventLabels:** {{ toJson .InvolvedObject.Labels}}\n**EventAnnotations:** {{ toJson .InvolvedObject.Annotations}}"
The default drop rule is: - type: "Normal", i.e. not true Normal Level for alerting;
Now add the following rules:
1 2 3 4 5 6 7 - source: host: "worker-1" - namespace: "cattle-monitoring-system" - name: "*emqx*" - kind: "Pod|Deployment|ReplicaSet" - labels: version: "dev"
... host: "worker-1": Not for the nodeworker-1 Make alarms;... namespace: "cattle-monitoring-system": No, NameSpace: cattle-monitoring-system Make alarms;... name: "*emqx*": Not included in name (name tends to be pod name). emqx of do alarmskind: "Pod|Deployment|ReplicaSet":Wrong Pod Deployment ReplicaSet Make alerts (that is, do not pay attention to application, component-related alarms)...version: "dev":Wrong label contain version: "dev" (you can block alarms for specific applications)
The final effect
As shown in the following figure:
🎉🎉🎉