How to configure SLO
This article was last updated on: July 24, 2024 am
preface
Whether it is a cloud company that provides IaaS PaaS SaaS externally, a Party B company that provides information technology services, or a data center and operation and maintenance department in various industries such as financial manufacturing, a very important contract commitment or assessment index is:SLA(i.e., Service-Level Agreement).
The most widely known is Google’s SRE theory.
Google SRE SLO & SLA
At Google,There is a clear distinction between SLOs and service level agreements (SLAs).SLAs typically involve promising service users that the service availability SLO should reach a specific level for a specific period of time.Failure to do so will result in some kind of punishment。 This may be a partial refund of the service subscription fee paid by the customer for that period, or an additional subscription time added free of charge. Failure to meet SLOs hurts the service team, so they will strive to stay within the SLO. If you’re charging your customers, you might need an SLA.
Availability SLOs in SLAs are typically more permissive than internal availability SLOs. This can be expressed in availability numbers: for example, 99.9% availability SLO within a month and 99.95% internal availability SLO. Alternatively, the SLA might specify only a subset of the metrics that make up the internal SLO.
If the SLO in the SLA is different from the internal SLO (which almost always is), monitoring must explicitly measure SLO compliance. You want to be able to see the availability of the system during the SLA schedule and quickly see if it seems to be in danger of falling out of SLO.
You also need to make precise measurements of compliance, typically from Metrics, Tracing, Logging analytics. Because we have an additional set of obligations for our paying customers (as described in the SLA), we need to measure the queries we receive from them separately from other queries. This is another benefit of establishing SLAs—it’s a clear way to prioritize traffic.
When defining an SLA availability SLO, be careful which queries are considered legitimate. For example, if a customer exceeds their quota because they published the wrong version of their mobile client, consider excluding all “over quota” response codes from the SLA.
SLI
SLI is a carefully defined measurement that determines what to measure based on different system characteristics.
Common SLIs are:
- performance
- Response time (latency)
- Throughput
- Request volume (QPS)
- Freshness
- usability
- Uptime
- Failure time/frequency
- reliability
- quality
- Accuracy
- Correctness
- Completeness
- Coverage
- Relevance
- Internal metrics
- Queue length
- RAM usage
- Factor people
- Time to response
- Time to fix
- Fraction fixed
SLO
SLO (Service Level Objective) specifies an expected state of functionality provided by a service, which is used by the service provider to specify the expected state of the system. There is no mention in the SLO about what happens if the goal is not met.
SLO is described in terms of SLI and is generally described as:
For example, the following SLO:
- Average QPS > 100 k/s per minute
- 99% access latency < 500ms
- 99% bandwidth per minute > 200MB/s
The target when setting an SLO depends on the different conditions of the system, and different SLOs are set according to different states:
总 SLO = service1.SLO1 weight1 + service2.SLO2 weight2 + …
Why SLO, and what are the benefits of setting up an SLO?
- For the customer, the expected quality of service simplifies the client’s system design
- For service providers
- Predictable quality of service
- A better cost/benefit trade-off
- Better risk control (when resources are constrained)
- Faster reaction in case of failure and taking the right action
SLA
SLA = SLO + 后果
brief summary
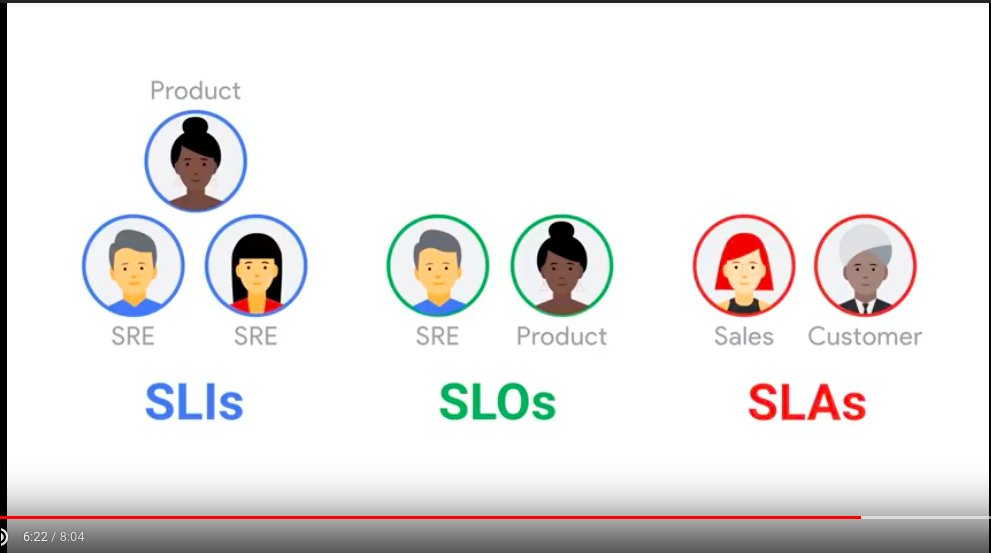
- SLI: Service level metrics, carefully defined metrics
- SLO: service level objectives,
总 SLO = service1.SLO1 weight1 + service2.SLO2 weight2 + … - SLA: Service Level Agreement,
SLA = SLO + 后果
How to configure SLO
Public cloud common SLOs
Commonly found in services or APIs that process requests through (e.g., Object Storage or API Gateway)
- Error rate calculates the total number of errors returned by the service to the user
- If the error rate is greater than X% (e.g. 0.5%), even if the service is down, start calculating downtime
- If the error rate persists for more than Y (e.g. 5) minutes, this downtime is counted
- Intermittent downtimes of less than Y minutes are not counted.
Front-end web or APP
Front-end user experience Apdex targeting
If you have front-end js probe monitoring, or dial-test monitoring, you can use front-end user experience Apdex as SLO.
Apdex defines a performance criterion that divides application users into three groups:
- satisfied
- Tolerable (fair)
- Frustrated (dissatisfied).
For example, as an SLO for a front-end application, you can specify that you want 90% of your users to be Apdex 满意 。
asMy WebApp The Apdex formula is as follows:
100% * (apps.web.actionCount.category:filter(eq(Apdex category,SATISFIED)):splitBy("My WebApp")) / (apps.web.actionCount.category:splitBy("My WebApp"))
The front-end APP has no Crash user rate target
One of the most important metrics for measuring the usability and reliability of mobile apps (iOS and Android). 无崩溃用户率。 REFERS TO THE PERCENTAGE OF USERS WHO OPEN AND USE MOBILE APPS WITHOUT CRASHING.
Therefore, the formula example is as follows:
apps.other.crashFreeUsersRate.os:splitBy("My mobile app")
Dial availability targets
Dial Test Availability SLO represents the percentage of time that a dial test is available, or the percentage of successful dial tests out of the total number of tests performed.
Therefore, the formula example is:
(synthetic.browser.availability.location.total:splitBy("My WebApp"))
Back-end app or service
Basic SLO - Call success rate target
成功率 = 成功的请求调用次数 / 总的请求调用次数
As:My service The Success Rate:
100% * (service.requestCount.successCount:splitBy("My service"))/(service.requestCount.totalCount:splitBy("My service"))
Well, if My service For a critical API or request that needs to be metered, it might be the following formula:
1 | |
ℹ️ prompt:
succeedOne of the simplest ways to request is that a request with an HTTP status code of 2xx or 3xx is considered successful.
In another way, a request that does not throw an error (log or exception) during request execution is considered successful.
Service performance targets
The point is:performance。
Service Performance SLO represents “fast” service calls as a percentage of total service calls, where “fast” is defined using custom conditions. For example:
- fast:0 - 3s service call completes ()
- Normal: Service calls complete within 3 - 5 seconds
- slow: 5s or more to complete the service call or timeout
ℹ️ prompt:
Of course, the 3S above should not be thought of in the head, but should be based on, for example, the response time of 99% when the system is up and running in the past month.
An example of a formula is:
(service:fastRequests:splitBy("My WebApp")) / (service:totalRequests:splitBy("My WebApp"))
Back-end database
Database availability or read availability targets
Error rate: is the number of failed SQL executions for the DB divided by the total number of SQL executions in a given one-hour interval.
Read error rate: is the number of failed query SQL executions for the DB divided by the total number of SQL executions in a given one-hour interval.
An example of a formula is:
可用性 % = 100% - Average DB Error Rate
Or:
读可用性 % = 100% - Average DB Read Error Rate
Throughput target
-
Throughput failed requests: Indicates that the request has not exceeded the given DB throughput, but is limited by the DB throughput, resulting in an error code
-
Throughput error rate: is the total number of failed requests for throughput for a given DB divided by the total number of requests in a given one-hour interval.
So, an example of the formula is:
吞吐量目标% = 100% -平均吞吐量错误率
Consistency goals
The SLI is:
Consistency violation rate: refers to successful requests in a given DB that cannot be sent when consistency guarantees are enforced for the selected consistency level (by total number of requests) within a given one-hour interval.
Delay target
- P99 latency: Calculated test SQL over a period of time (e.g
select 1 from dual99% percentile response time of execution time. - **Delay time and **: Refers to the total number of one-hour intervals in which successful SQL requests submitted by an application result in a P99 latency greater than or equal to 10ms.
So, the example formula is:
延迟目标% = 100% - 总的延迟时间和的次数 / (DB 总使用时间/1H)
For example, in the past 1 month, the total delay time and number of times is 50, and the denominator is:30 * 24 / 1 = 720
So:延迟目标% = 100% - 50 / 720 ≈ 93%
MQ class
Message success rate target
This is the successful message divided by the total message received by MQ.
An example of a formula is:
(100)*((mq.rabbitmq.queue.requests.successful:splitBy("payment"))/mq.rabbitmq.queue.requests.incoming:splitBy("payment")))
Host class
UPTIME target
For example, Hourly Uptime % = 100% - The percentage of the total amount of time a single Host instance has been unavailable (not more than how long it has been unavailable).
Unavailable definitions can be:
- The Host instance has no network connectivity
- The Host instance cannot perform read and write IO, and IO is suspended in the queue. i.e. IO hang.
K8S class
The K8S class is a comprehensive system that needs to consider the following objectives
- API Server success rate target
- Compute target
- Storage target
- Network destination
- …
Storage class
Availability target
This is roughly similar to the availability target above.
Data durability goals
This is usually very high, for example: 99.9999999999%
It can be simply and crudely believed that as long as there is data loss, it has not achieved the goal.
The typical case is Tencent’s.
Network class
Availability targets
Take a NAT gateway as an example:
The number of minutes that a single-instance service is unavailable: When all packets from the outbound direction of a NAT gateway instance are dropped by the NAT gateway gateway within a certain minute, the NAT gateway instance service is considered unavailable for that minute. The sum of the minutes that a NAT gateway instance is unavailable in a service cycle is the number of minutes of service unavailability.
summary
Different SLOs can be set according to different levels and components.
Monitoring of SLOs requires the support of monitoring tools.
Commonly used SLOs include:
- Availability target
- Success Rate target
- Latency target
- Uptime target
- Data durability goals
EOF