Introduction to DRBD
This article was last updated on: July 24, 2024 am
description
Introduction to DRBD, a data mirroring software
Distributed Replicated Block Device (DRBD) is a software-based, network-based block replication storage solution.It is mainly used for data mirroring of disks, partitions, logical volumes, etc. between servers。 When the user writes data to the local disk, the data will also be sent to the disk of another host in the network, so that the data of the local host (master node) and the remote host (standby node) can be synchronized in real time, and when the local host has a problem, the remote host still retains a copy of the same data, which can continue to be used to ensure the security of the data.
Basic functionality of DRBD
The core function of DRBD is data mirroring, which is implemented by mirroring the entire disk device or disk partition through the network, and transmitting the data of one node to another remote node in real time through the network to ensure the consistency of data between the two nodes, which is somewhat similar to the function of a network RAID1。 For DRDB data mirroring, it has the following characteristics:
- Real-time。 Data replication occurs immediately when an app has a modification operation on disk data.
- transparency。 The application’s data is stored transparently and independently on the mirror device. Data can be stored on different web-based servers.
- Synchronous mirroring。 When the local application requests a write operation, the write operation also starts on the remote host.
- Asynchronous mirroring。 Writes to the remote host do not begin until the local write operation has completed.
Composition of DRBD
DRBD is a distributed storage system in the Linux kernel storage layer, specifically composed of two parts, one is a kernel template, which is mainly used to virtualize a block device; One is the user space management program, which is mainly used to communicate with the DRBD kernel module to manage DRBD resources, in DRBD, resources mainly include DRBD devices, disk configurations, network configurations, etc.
DRBD device in the entire DRBD system is located above the physical block device, under the file system, between the file system and the physical disk to form a middle layer, when the user writes data in the file system of the active node, the data will be intercepted by the DRBD system before being officially written to the disk, and at the same time, when DRBD captures the operation with disk write, it will notify the user space management program to copy these data, write it to the DRBD image of the remote host, and then store it in DRBD The remote host disk that is mapped by the mirror.
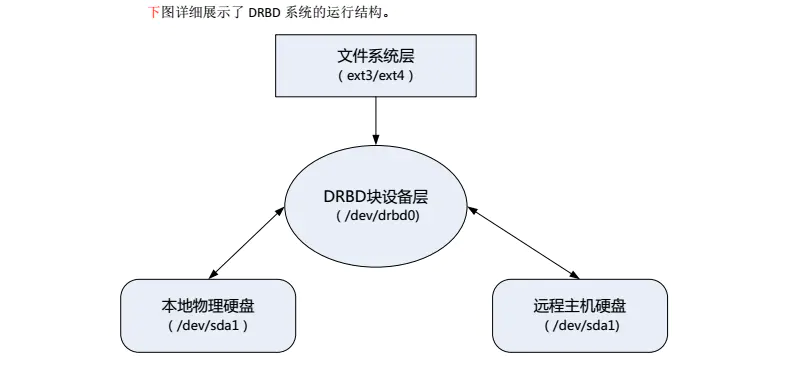
**DRBD is responsible for receiving data, writing it to a local disk, and sending it to another host. The other host then saves the data to its own disk. DRBD9 previously allowed only one node at a time for read and write access, which was sufficient for typical failover high-availability clusters. DRBD9 and later will support read and write access from two nodes.
Key features of DRBD
DRBD system has many useful features in realizing data mirroring, and we can choose the functional features that suit us according to our own needs and application environment. The following describes several very important application characteristics of DRBD.
- Single-master mode: This is one of the most frequently used modes, mainly used in the data storage of high-availability clusters, to solve the problem of data sharing in the cluster, in this mode, only one master node in the cluster can read and write data, and the file systems that can be used in this mode are ext3, ext4, xfs, etc.
- Dual primary mode: This mode can only be used in DRBD8.0 and later versions, mainly used in load balancing clusters, to solve data sharing and consistency problems, in this mode, there are two master nodes in the cluster, because both master nodes may perform concurrent read and write operations on data, so a single file system can not meet the demand, at this time a shared cluster file system is needed to solve the problem of concurrent read and write. The file systems commonly used in this mode include GFS, OCFS2, etc., and the distributed lock mechanism of the cluster file system can solve the problem of two master nodes in the cluster operating data at the same time.
Copy mode
DRBD provides three different replication methods, namely:
- Protocol A, as long as the local disk write has completed and the packet is already in the send queue, a write operation is considered complete. In the event of a remote node failure or network failure, data loss may occur, because the data to be written to the remote node may still be in the sending queue.
- Protocol B, as long as the local disk write has completed and the packet has reached the remote node, a write operation is considered complete. In this way, data loss may occur in the event of a failure of the remote node.
- Protocol C, only the disks of the local and remote nodes have confirmed that the write operation is complete, and the write is considered to have completed a write operation. This way without any data loss,Protocol C is currently the most widely used, but in this way, the I/O throughput of the disk depends on network bandwidth. This method is recommended when the network bandwidth is good.
Enterprise scenarios for DRBD
In production scenarios, there will be many data synchronization solutions based on highly available server-to-DRBD.
For example:
- Storage data synchronization:
heartbeat+drbd+nfs/mfs/gfs - Database data synchronization:
heartbeat+drbd+mysql/oracleWait.
In fact, DRBD can be used in any application scenario of all services that require data synchronization.
Installation and configuration
Configure DRBD
We are /etc/drbd.d Create one below mydb.res File. The following is a simple example of two DRBD host node profiles
resource "mydb" { #资源名字为mydb
protocol C; #使用DRBD的第三种同步协议,表示收到远程主机的写入确认后认为写入完成
net {
cram-hmac-alg "sha1"; #DRBD同步时使用的验证方式
shared-secret "passwd";
}
syncer { #数据同步传输控制
rate 200M; #最大同步速率,下面两个是辅助参数
al-extents 257;
on-no-data-accessible io-error;
}
disk { #处理发生数据不同步的问题,新的版本已不使用
on-io-error detach;
fencing resource-only;
}
startup { #启动时的参数设置
wfc-timeout 30; #等待30s服务启动
outdated-wfc-timeout 20;
degr-wfc-timeout 30;
}
on join { #主机名
device /dev/drbd0; #drbd的块设备名
disk /dev/sdb1;
address 192.168.99.131:7788; #drbd的监听端口,用于主机通信
meta-disk internal; #元数据的存放方式(默认)
}
on jinbo {
device /dev/drbd0;
disk /dev/sdb1;
address 192.168.99.132:7788;
meta-disk internal;
}
}
DRBD management and maintenance
DRBD status
View node status on any node
Log in to any drbd node and execute cat /proc/drbd command, the output is as follows:
[root@jinbo drbd.d]# cat /proc/drbd
0: cs:Connected ro:Secondary/Secondary ds:Inconsistent/Inconsistent C r-----
ns:0 nr:0 dw:0 dr:0 al:0 bm:0 lo:0 pe:0 ua:0 ap:0 ep:1 wo:f oos:20964116
The meaning of the output is explained as follows (common)::
CS connection status:
-
StandAlone is independent: The network configuration is not available. The resource has not been connected or disconnected (used) by the administrator
drbdadm disconnectcommand), or due toAuthentication failedOr is itSplit brainsituation. -
Disconnecting disconnects: The disconnect is only a temporary state, and the next state will be StandAlone alone.
-
Unconnected dangling: is the temporary state before the connection is attempted, and the possible next states are WFconnection and WFReportParams
-
Timeout timeout: The connection to the peer timed out, which is also a temporary state
-
WFConnection Wait for network connectivity to be established with the peer
-
WFReportParams: A TCP connection has been established and this node is waiting for the first network packet from the peer
-
Connected Normal connection
-
SyncSource: Synchronization with this node as the synchronization source is in progress
-
SyncTarget: Synchronization with this node as the synchronization target is in progress
-
ro: That is, roles, the roles of local node and remote node, when DRBD is started for the first time, both DRBD nodes are in the Secondary state by default.
-
ds: i.e. disk states, the hard disk status of local and remote nodes, “Inconsistent/Inconsistent” means “inconsistent/inconsistent state”, which means that the disk data of the two nodes is in an inconsistent state
-
C: indicates the protocol used when C
The following six represent I/O status flags
r或s: indicates that the I/O operation is in progress, s indicates that the I/O is suspended, normal r-或a:a indicates a delay before synchronization-或p:p represents a situation in which data resynchronization occurs because the peer layer initiates a synchronization hang-或u:u indicates a data resync situation caused by a locally initiated synchronization pending-或d,b,n,a: d indicates I/O blocking due to internal causes of drbd, similar to a transitional disk state; b indicates that standby device I/O is blocking; n indicates the blocking of network sockets; a indicates that both I/O device blocking and network blocking occur-或s:s represents the flag when an updated activity log is suspended.
The following tags represent performance indicators (the main first 4 items)
ns: Network send, which represents the amount of data sent to a peer over the network, in kbytenr: or network receive, which indicates the amount of data received from peers over the networkdw: is disk write, which represents network data written to local assetsdr: that is, disk read, which represents the network data read from the local disk
DRBD primary/standby node switchover
When the system is maintained, or in a high-availability cluster, when the primary node fails, the roles of the primary and standby nodes need to be reversed. There are two ways to switch the active and standby nodes: stop the DRBD service switchover and switch normally.
1. Stop the DRBD service switchover
If the primary node service is shut down, the mounted DRBD partition is automatically unmounted on the primary node, perform the following operations:
1 | |
Then check the DRBD status of the standby node:
1 | |
As you can see from the output, the status of the current primary node changes to “unknown”, and then execute the switch command on the standby node:
1 | |
Therefore, you must execute the following command on the standby node:
1 | |
or
1 | |
Now switch normally, and then check the status of this node. It can be seen that the original standby node is already in the primary state, and the original primary node is still in the Unknown state because the DRBD service is not started, and after the original primary node service is started, it will automatically become Secondary state, and there is no need to execute the command to switch to the standby node again on the original primary node
Finally, mount the DRBD device on the new primary node to complete the switchover of the primary and standby nodes
2. Switch normally
1 | |
Treatment of split brain
If the peer node of drbd is not online,That is, if the data changes of the primary node cannot be transmitted to the standby node in time for a certain period of time, data inconsistency will occur, and even if the failed node is restored after going offline, DRBD may not be able to synchronize normally。 Or in another case, the master and backup are online, but the heartbeat network is broken and there is a brain split, and both nodes think that they are the primary node, which will also cause the data inconsistency between the two nodes, which requires manual intervention to tell drbd which node to take as the main node, or configure the behavior of brain splitting in dbrd. The following are the conditions that occur after the standby node is not online for a long time:
To view the status of the standby node:
1 | |
- CS (Connection State), orphaned
- ro (role),
Secondary/Unknown - DS (Disk Status) is
uptodate/unknown, the local node is in the updating state, and the peer node is in the unknown state. As can be seen from the above, the backup node has a DRBD brain split.
After the occurrence of brain split, it is necessary to think that it is necessary to confirm which node has the latest data, then which node is the mainstay, for example, after the brain split, the master-drbd node data is the latest, then the master-drbd node data prevails, and then restore and manually synchronize.
Manual recovery of split brain
The steps are as follows:
- Set slave-drbd on slave-drbd to slave node and discard resource data
1 | |
- Manually connect resources on the master-drbd master:
[root@master-drbd /]#drbdadm connect mydb
In this way, the problem of split-brain is solved, and the master-slave node begins to synchronize data again