Summary of the pitfalls that Prometheus Alertmanager has trodden through production configuration
This article was last updated on: July 24, 2024 am
Brief introduction
Alertmanager Handles alerts sent by client applications, such as Prometheus server. It is responsible for deduplicating, grouping, and routing them to the correct receiver integration, such as email, WeChat, or DingTalk. It is also responsible for handling silencing, timed send/do not send (Mute), and inhibition of alarms.
As an open source alerting application designed for Prometheus, AlertManager already has a variety of rich, flexible, and customizable functions of alerting applications:
- Deduplicating: For example, in a high-availability AlertManager deployment, the same alarm is sent to all high-availability nodes at the same time, and it will be deduplicated according to the hash
- Grouping: For example, it can be based on
AlertName,Instance,Joband other labels to group massive alarms. Typically, suddenly a lot of pods are issuedAlertName: InstanceDownAlerts, then directly based onAlertNameIt is sent in groups so that the user receives only onexxx 个 Pods InstanceDownAlert email. Greatly reduce the amount of receiving by the alarm receiver. - Routing (routing): Send the alarm to follow up with certain filter conditions to the specified receiver. Such as: satisfied
job=dbof alarms are routed to the DBA; satisfyteam=team-AAlerts are routed to team-A’s mail group… - Receiver: Specific notification channel + recipient. Such as: email notification channel + DBA mailbox; DingTalk notification channel + SRE contact;
- Silent/shielding: For example, the application release period, block related alarms.
- Timed send/do not send (Mute): If working hours (965, 5 days a week) are sent through the mail channel; Non-working hours (off-hours, weekends, holidays) normal channel mute, only sent to on-call personnel through the on-call channel
- Inhibition: In common scenarios, after the high-level alarm is triggered (firing), the low-level alarm does not need to be sent. For example: disk space
criticalThe level alarm has been triggered (space usage exceeds 90%), at this timewarningLevel alarms (space usage greater than 80%) are suppressed.
In addition to no multi-tenant function, no good UI interface, no alarm history statistics display, as an alarm application, AlertManager is already very powerful. 👍️👍️👍️
The AlertManager production configuration wades through the pit
Let’s not go to the point: the pit that AlertManager production configuration has traversed
📝Notes:
All of the following are based on the latest version of AlertManager at 20220723: v0.24
URL-related configuration
demand
- The displayed URL looks like this:
https://e-whisper.com/alertmanager/#/alerts- It’s a domain name
- There is one
/alertmanager/prefix
- When a request goes to the AlertManager component, the default situation remains unchanged, such as
https://10.0.0.1:9093/#/alerts
Namely: the path sent by the reverse proxy is different from the one used by the user.
implement
Ingress level implementation
Here is directly implemented using Traefik, which has been written about before, see here:
AlertManager configuration
AlertManager here requires 2 static parameters to be configured, which are added in StatefulSets in AlertManager alertmanager --<flags> to achieve .
By default, Prometheus (and Alertmanager) assume that the external URL (-web.external-url) is a prefix path that will appear in all requests sent to it. However, this is not always the case,--web.route-prefix Flags allow you to control this more granularly.
With the following configuration, this will be stripped before the request is delivered to AlertManager/alertmanager/。 In this case, you need to specify what the URL the user uses in their browser https://e-whisper.com/alertmanager/ The prefix that Prometheus sees in its HTTP requests is not/alertmanager/, but just empty/。
1 | |
A small pit
After the above configuration, it is perfect, but when I check the content of the email, I found a small pit:
- The default mail template at the bottom
Sent by Alertmanagerurl does not/, causing the URL to not jump normally after clicking.
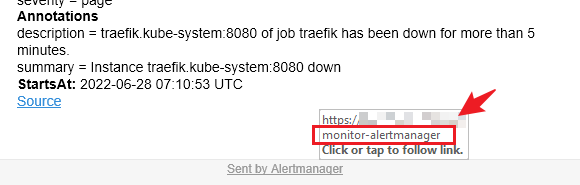
Here is the auto-add via Ingress-Traefik / features, you can see another article:
The default automatic Resolved alarm pits
If you haven’t read the documentation in detail, just use the default configuration, and AlertManager’s alert source has other monitoring software besides Prometheus. You will find a situation: every 5 minutes, some alarms that are still being triggered are automatically resolved!
This is because there is one in the default AlertManager configuration resolve_timeout parameter, and its default configuration is: resolve_timeout: 5m.
📚️Reference:
ResolveTimeout is the default value used by alertmanager, if alerts do not include EndsAt, after this time, if alerts are not updated, AlertManager will declare it resolved.
This parameter has no effect on alerts from Prometheus, as they always include EndsAt.
Here it is Automatic Resolved The reason, when I first came across, I looked, this is easy to do, I want to disable this feature, although this parameter cannot be disabled. If I had to add a term to this love, I would like it to be 10,000 years, set directly 10000y Come on.
The result was wrong… 😂😂😂
This one duration On the documentation, it clearly says that it is:
📚️Reference:
<duration>: The duration of the regular expression match((([0-9]+)y)?(([0-9]+)w)?(([0-9]+)d)?(([0-9]+)h)?(([0-9]+)m)?(([0-9]+)s)?(([0-9]+)ms)?|0)As.1d,1h30m,5m,10s
But settings 10000y satisfy ([0-9]+)y) but reported an error. 😂
Then I looked through various source codes, and finally found this <duration> is not possible to set to the three-digit y: setting 100y Error, Settings 99y Normal operation.
So, you want to disable AlertManager Automatic Resolved function, just set it up like this: resolve_timeout: 99y
By default, 4H unresolved alarms automatically resend the pit of alarm notifications
No matter who it is, I think I hope that the fewer alert emails I receive every day, the better, so that I can follow up and solve them one by one.
As a result, AlertManager poured well. "Sweet"The ground provides4H Unresolved alerts are automatically reissued function. 😂😂😂
This is because there is one in the default AlertManager configuration repeat_interval parameter, and its default configuration is: repeat_interval: 4h…
Still like last time, I want to disable this function, although this parameter cannot be disabled (if it is set to 0, it will not be disabled, but will report an error: repeat_interval cannot be zero), If I had to add a term to this love, I would like it to be 10,000 years, set directly 10000y Come on.
The result is wrong again (strictly speaking, warning)… 😂😂😂
1 | |
📚️Reference:
repeat_interval is greater than the data retention period. This can cause notifications to repeat more often than expected.
Other words repeat_interval Setting it too large may cause the notification to repeat more frequently, if you want to set it as large as possible, and not greater than the data retention time.
So, you want to keep AlertManager as low as possible Unresolved alerts are automatically reissued The frequency, just set like this: repeat_interval: <尽可能大, 但不要大于数据的保留(data retention)时间
Set the data retention period for AlertManager
Continuing from the above, what is the default AlertManager data retention period? If you want to adjust it, how do you adjust it?
Searched for a document, but couldn’t find it 😂😂😂
Why I didn’t find it, here’s why:
📚️Reference:
The Alertmanager is configured via command-line flags and a configuration file.
Command-line flags configure immutable system parameters, while configuration files define suppression rules, notification routes, and notification recipients.
The documentation is not about Command line flag configuration of the content. Where can I find it? run alertmanager -h command, the result is as follows:
📝Notes:
Only the display part, there are many flags related to the cluster, but it is not shown.
1 | |
You can see: --data.retention=120h The default is 120h, 5 days.
Too little, instead --data.retention=90d, it turned out to be wrong again, this time in the format, which should be 😂😂😂 written as: --data.retention=--data.retention=2160h
Then correspondingly, the above parameters can be set to: repeat_interval: 90d (Yes, you read that right, it can be written here as 90d … 😅😅😅)
Complete production practice AlertManager configuration
Finally, to give you a complete production practice AlertManager configuration, for reference:
Immutable parameters (and command-line flags)
'--storage.path=/alertmanager'(Storage location, production of this directory needs to configure persistent storage)'--config.file=/etc/alertmanager/alertmanager.yml'(Configuration file location, which can be saved and used in production via ConfigMap)'--cluster.advertise-address=[$(POD_IP)]:9094'(Highly available cluster port 9094)'--cluster.listen-address=0.0.0.0:9094'(Highly available cluster port 9094)--cluster.peer=alertmanager-0.alertmanager-headless:9094(A peer of a highly available cluster; Need to create a headless service)--cluster.peer=alertmanager-1.alertmanager-headless:9094(Another peer of the highly available cluster)--cluster.peer=alertmanager-2.alertmanager-headless:9094(Third peer of a highly available cluster)'--data.retention=2160h''--log.level=info'(Log level, DevTest Environment can be set to.)debug)'--web.external-url=https://e-whisper.com/alertmanager/''--web.route-prefix=/'
Variadic parameters (parameters in a configuration file)
1 | |
Specific route, receiver, inhibit and other configurations are not reflected.
Above.
🎉🎉🎉