Reading Notes: "Large-scale Distributed Storage Systems: Principles and Architecture in Action": IV
This article was last updated on: July 24, 2024 am
🔖 Books:
“Large-scale Distributed Storage System: Principles Analysis and Architecture Practice”
By Yang Chuanhui
4 Distributed File System
4.1 GFS
4.1.1 System Architecture
Subassembly:
- GFS Master
- GFS ChunkServer (CS Block Server)
- GFS client
GFS files are divided into fixed-size databases (chunks), and the master server allocates a 64-bit globally unique chunk handle when it is created.
Chunk copies multiple copies in different machines, defaulting to 3 copies.
Master serverThe metadata of the system is maintained, including files and chunk namespaces, file-to-chunk mappings, and chunk location information. It is also responsible for the global control of the entire system, such as chunk lease management, garbage collection useless chunk, chunk replication, etc. The master server periodically exchanges information with CS in a heartbeat.
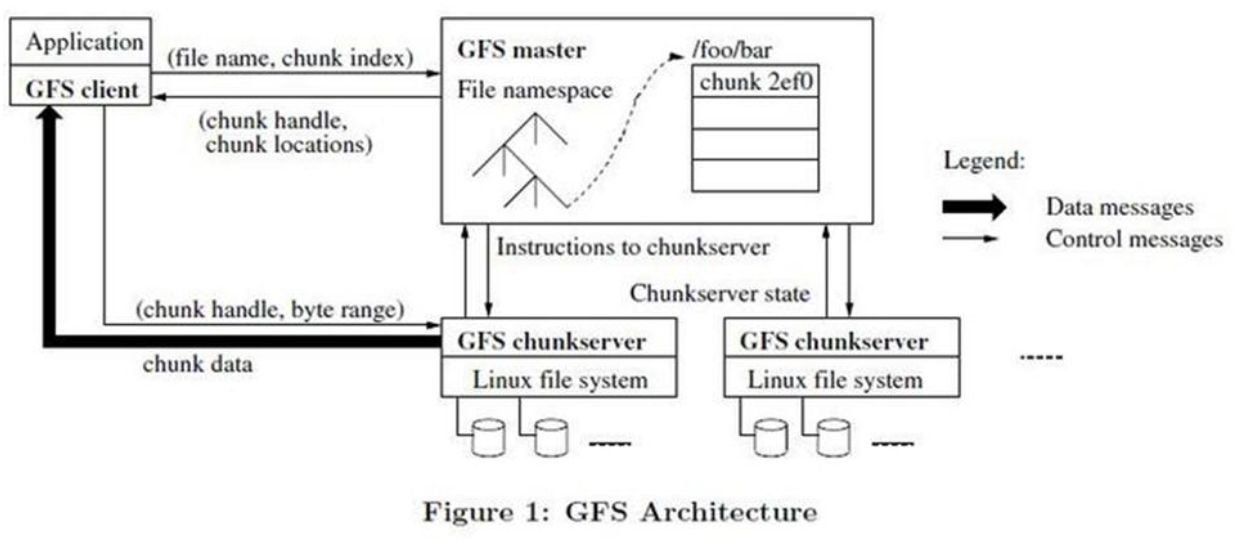
clientis the provider that GFS provides to an application, which is a set of private interfaces that do not follow the POSIX specification and are provided as library files. The client accesses the master node, obtains the CS information that interacts with it, and then accesses the CS directly to complete the data access.
❗ Note:
Clients in GFS do not cache file data, only metadata obtained from the master server.
4.1.2 Key Issues
Lease mechanism
GFS data append is based on records, each record size ranges from tens of KB to several MB, if each record append needs to request Master, the Master will become a bottleneck, so the GFS system through the lease mechanism to authorize chunk write operations to ChunkServer. The one who owns the lease authority is the primary ChunkServer, and the ChunkServer where the other replicas reside is called the standby ChunkServer.Lease authorization is for a single chunk, during the lease period, writes to the chunk are the responsibility of the master ChunkServer, thereby reducing the load on the master. Generally speaking, the validity period of the lease is relatively long, such as 60s, as long as there is no abnormality, the main ChunkServer can continue to request the master to extend the validity period of the lease until the entire chunk is full.
GFS solves this problem by maintaining a version number for each chunk, and each time the chunk is leased or the main ChunkServer re-extends the lease period, the Master will increase the version number of the chunk by 1. If A2, a copy of A chunk goes offline during the process, the version number of A2 will be low, and A2 will be marked as a destructible chunk, and the master’s garbage collection task will check regularly and notify ChunkServer to recycle A2.
Consistency model
GFS is mainly for:supplement(append) insteadRewrite(overwrite) by design.
Append the model
Fault tolerance mechanism
Master fault tolerance
It is done by means of operation log and checkpoint, and there is a “Shadow Master” real-time hot backup.
Three types of metadata information are saved on the master:
- NameSpace, that is, the directory structure of the entire file system and the basic information of chunk;
- Mapping between files to chunks
- Location information for chunk copies, each chunk usually has 3 copies
The master operation always records the operation log before modifying the memory.
The remote live hot standby will receive the operation logs sent by the master in real time and play back these metadata operations in memory. If the master is down, you can also switch to real-time standby in seconds to continue providing services.
Master needs to persist namespaces and file-to-chunk mappings; The location information of the chunk copy can be unpersisted because the chunkserver maintains it.
ChunkServer is fault-tolerant
Multiple copies. For each chunk, all copies must be successfully written to be considered a successful write.
ChunkServer maintains a checksum on the stored data.
GFS to 64MB Divide the file for chunk size, each chunk is divided into blocks, block size is 64KB, each block corresponds to a 32-bit checksum. When reading a chunk copy, the ChunkServer compares the read data to the checksum, and if it does not match, an error is returned and the client selects a replica on a different ChunkServer.
4.1.3 Master Design
Master memory occupancy
Each chunk has less than 64 bytes of metadata. Then the chunk metadata size of 1PB of data does not exceed it 1PB * 3 / 64MB * 64 = 3GB
Master also compresses namespaces, and each file has no more than 64 bytes of metadata in the file namespace. Therefore, the master memory capacity does not become a system bottleneck for GFS.
Load balancing
There are 3 scenarios for creating a replica:
- Chunk created
- Chunk replication (re-replication)
- Load balancing (rebalancing)
How to choose the initial location of the chunk copy:
- The disk utilization of the ChunkServer where the new replica resides is below average
- Limit the number of “recent” creations per ChunkServer
- All copies of each chunk cannot be in the same rack.
Garbage collection
A mechanism for delaying deletion. Rename the file to a hidden name in the metadata and include a delete timestamp (3 days by default).
Garbage collection is generally performed during off-peak service hours, such as 1:00 a.m.
snapshot
Using the standard copy-on-write mechanism to generate snapshots, “snapshots” only increase the reference count of the chunk in GFS, indicating that the chunk is referenced by the snapshot file, and when the client modifies the chunk, it is necessary to copy the chunk’s data in the chunkServer to generate a new chunk, and subsequent modification operations fall on the newly generated chunk.
To take a snapshot, you first need to stop the write service of this file (reclaim through the lease mechanism), and then increase the reference count of all chunks in this file, and when you modify these chunks later, you will copy and generate new chunks.
4.1.4 ChunkServer design
Ensure that ChunkServer is distributed across different disks as evenly as possible. When you delete a chunk, you can only move the corresponding chunk file to the recycle bin of each disk, and the new chunk can be reused later.
4.1.5 Discussion
Typical benefits: Significantly lower costs, and Gmail services offer users more capacity for free due to low infrastructure costs.
4.2 Taobao File System
Before 2007, Taobao image storage systems used NetApp storage systems.
TFS: Blob storage system.
TFS architecture design considers the following 2 questions:
- Metadata information storage. The number of pictures is huge, and a single machine cannot fit all the metadata information.
- Reduce the number of IO times for picture reads.
Design Ideas:Multiple logical picture files share a single physical file
4.2.1 System Architecture
TFS does not maintain a file directory tree, and each small file is represented by a 64-bit number.
A TFS cluster consists of:
- 2 NameServer nodes (one primary and one standby)
- Multiple DataServer nodes
NameServer detects the DataServer by heartbeat.
Each DataServer runs multiple DSP processes, one dsp corresponds to one mount point, and this mount point generally corresponds to a separate disk, thereby managing multiple disks.
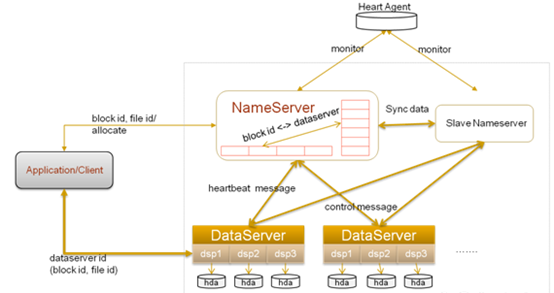
In TFS, a large number of small files (actual data files) are combined into one large file, called a block, and each block has a unique number (block ID) within the cluster, passing块 ID,文件编号 A file can be uniquely identified. Block data size is generally 64 MB, default 3 copies.
Append process
TFS is write-less-read-more, so every write goes through NameNode without any problem.
In addition, TFS does not need to support GFS multi-client concurrent append operations, each block can only have one write operation at a time, and the write operations of multiple clients will be serialized.
NameServer
Function:
- Block management, including creation, deletion, replication, rebalancing;
- DataServer management, including heartbeat, DataServer onboarding and exit;
- Manage the mapping between the Block and the DataServer in which it resides
Compared to GFS, TFS NameServer:
- There is no need to save file directory tree information;
- There is no need to maintain mappings between files and blocks
4.2.2 Discussion
- Image deduplication: MD5 or SHA1
- Image updated on Delete
4.3 Fackbook Haystack

- Directory
- Store
- Cache