Kafka best practices
This article was last updated on: February 7, 2024 pm
preface
Kafka best practices, involveing:
- Typical usage scenarios
- Best practices used by Kafka
Typical use cases for Kafka
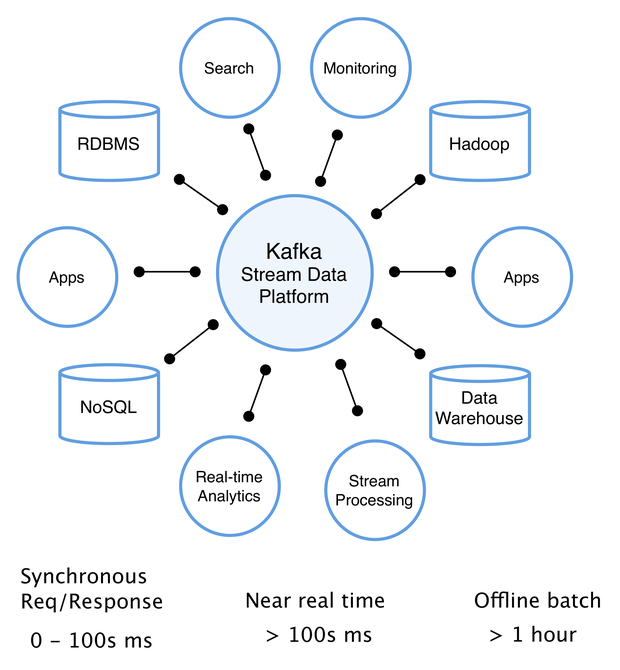
Data Streaming
Kafka can be docked with many mainstream stream data processing technologies such as Spark, Flink, and Flume. Taking advantage of Kafka’s high throughput, customers can establish a transmission channel through Kafka to transmit massive data on the application side to the stream data processing engine, and after data processing and analysis, it can support various services such as back-end big data analysis and AI model training.
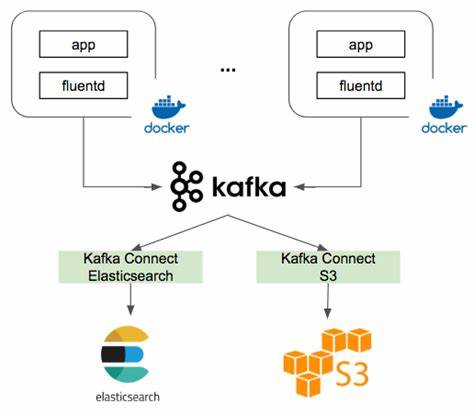
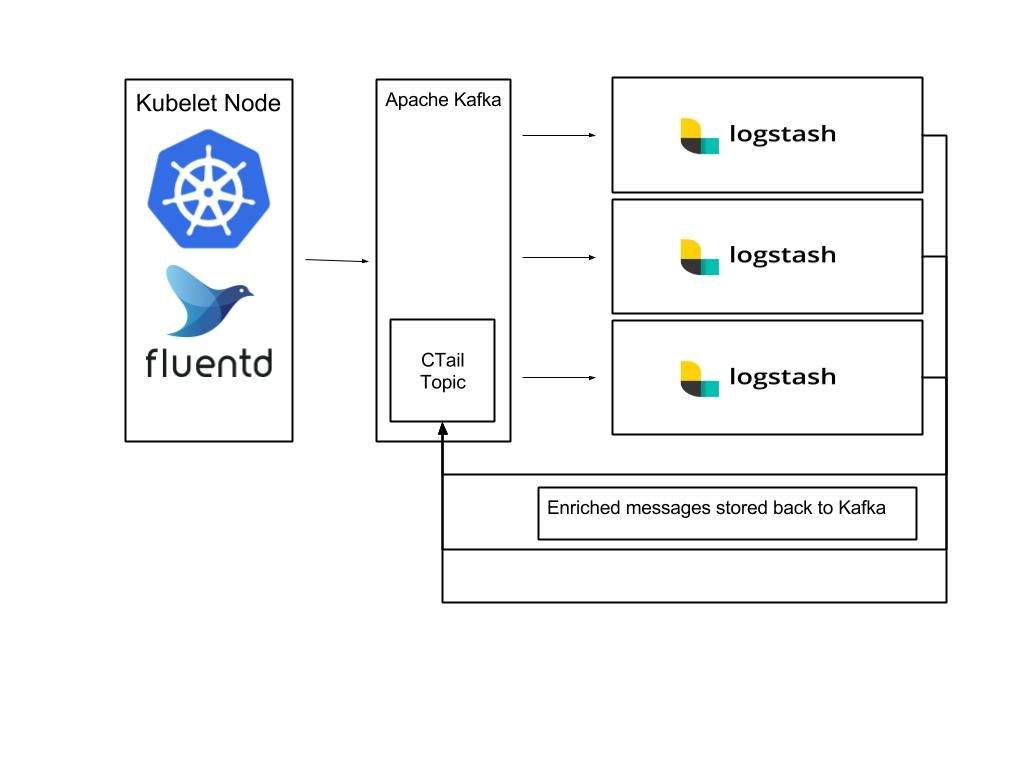
Log platform
The most commonly used scenario by Kafka, and the scenario I am most familiar with, is the log analysis system. The typical implementation is to deploy a log collector (such as Fluentd, Filebeat or Logstash) on the client side for log collection, send the data to Kafka, and then perform data operations through the back-end ES, and then build a display layer such as Kibana for statistical analysis data display.
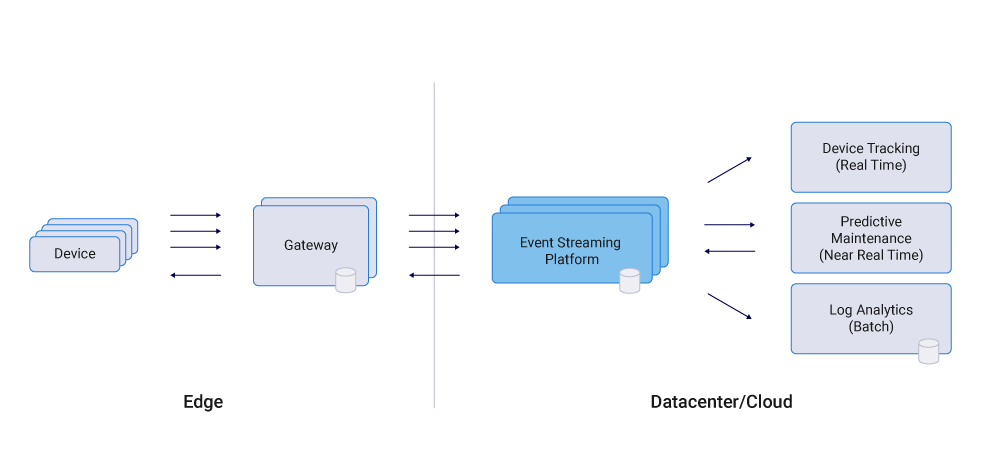
Internet of Things
With the emergence of valuable use cases, the Internet of Things (IoT) is gaining more and more attention. However, a key challenge is integrating equipment and machines to process data in real time and at scale. Apache Kafka and its surrounding ecosystems, including Kafka Connect and Kafka® Streams, have become the technology of choice for integrating and processing such datasets.
Kafka is already being used in many IoT deployments, including consumer IoT and Industrial IoT (IIoT). Most scenarios require reliable, scalable, and secure end-to-end integration to support real-time, two-way communication and data processing. Some specific use cases are:
- Connected automotive infrastructure
- Smart cities and smart homes
- Smart Retail and Customer 360
- Smart manufacturing
The specific implementation architecture is shown in the following figure:
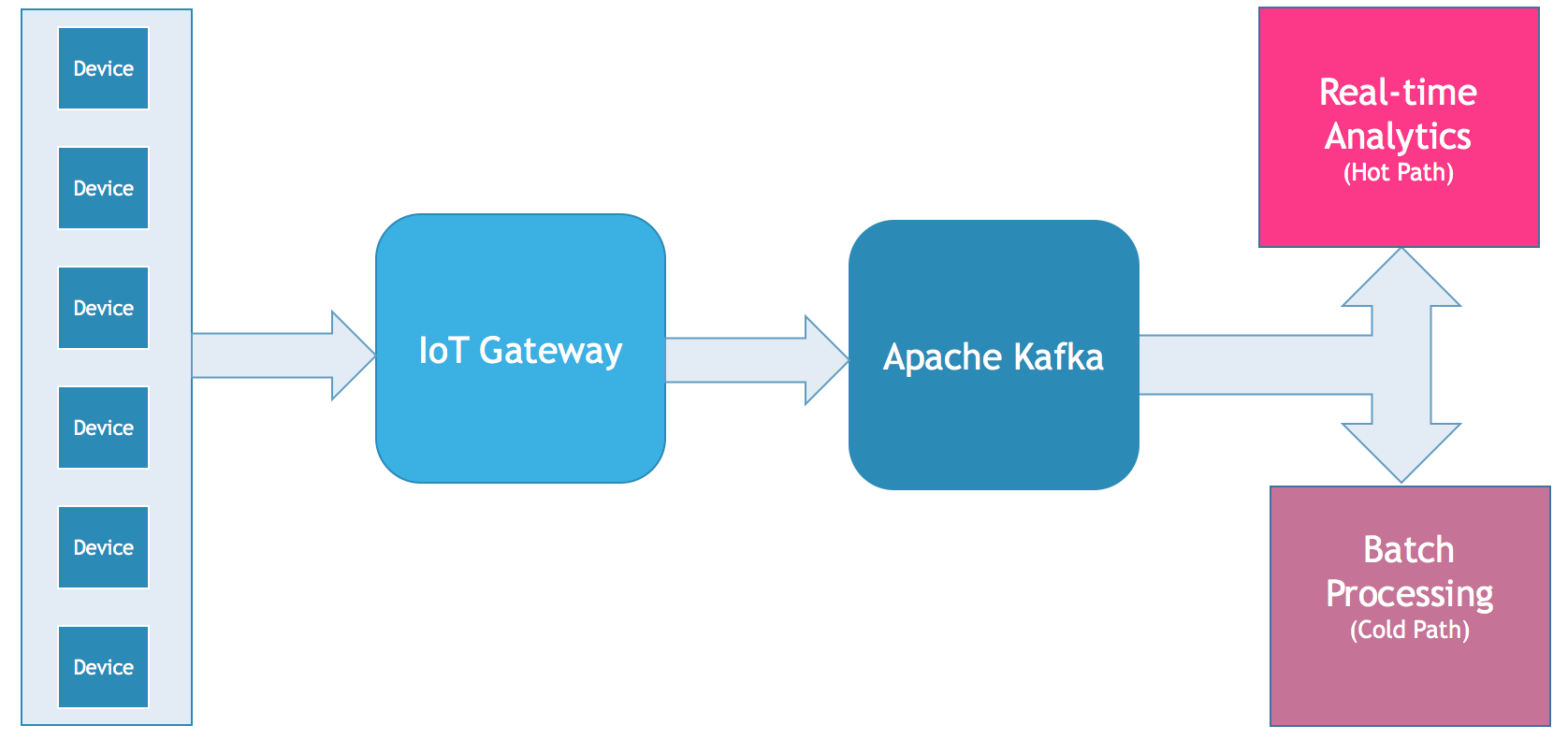
Best practices used
Reliability best practices
Meet different reliability based on producer and consumer configurations
Producer At Least Once
Producers need to set up request.required.acks = ALL, the server master node is successfully written and the standby node is synchronized successfully.
Consumer At Least Once
After the consumer receives the message,The corresponding business operation should be performed first, followed by a commit to identify that the message has been processedThis processing ensures that a message can be reconsumed if business processing fails. Pay attention to the consumer’s enable.auto.commit The parameter needs to be set to Falseto ensure that the commit action is controlled manually.
Producer At Most Once
To ensure that a message is delivered at most once, you need to set this setting request.required.acks = 0, set at the same time retries = 0。 The principle here is that the producer does not retry any exception and does not consider whether the broker responds successfully in writing.
Consumer At Most Once
To ensure that a message is consumed at most once, the consumer needs to be presentAfter receiving the message, commit to identify that the message has been processed, and then perform the corresponding business operation。 The principle here is that consumers do not need to care about the actual business processing results, and immediately commit to tell the broker that the message processing is successful after getting the message. Pay attention to the consumer’s **enable.auto.commit The parameter needs to be set to False**to ensure that the commit action is controlled manually.
Producer Exactly-once
Kafka 0.11 has been addedIdempotent messagesThe semantics of the setting enable.idempotence=true parameters, can be implementedSingle partitionMessage idempotent.
If a topic involves multiple partitions or requires multiple messages to be encapsulated into a transaction capable of being protected, you need to increase the transaction control, such as the following:
1 | |
Consumer Exactly-once
Setup required isolation.level=read_committed, and set it enable.auto.commit = falseTo ensure that consumers only consume messages that the producer has already committed transactions, consumer businesses need to ensure transactionality to avoid duplicate processing of messages, such as persisting messages to a database and then committing commits to the server.
Select the appropriate semantics according to the business scenario
Use At Least Once semantics to support a business that accepts a small number of message duplications
At Least Once is the most commonly used semantic that ensures that messages are only sent and consumed, with a good balance of performance and reliability, as it can beBy defaultmode.The business side can also guarantee idempotency by adding a unique business primary key to the message bodyOn the consumer side, ensure that messages with the same business primary key are processed only once.
Using Exactly Once semantics underpins businesses that require strong idempotency
Exactly Once semantics generally use a key business that absolutely does not tolerate duplication, typical cases areScenarios related to orders and payments。
Use At Most Once semantics to support non-critical business
At Most Once semantics are generally used inNon-business criticalbusinessNot sensitive to message loss, you just need to try to ensure that the message is successfully produced and consumed. A typical scenario for using At Most Once semantics isMessage notifications, where a small number of missed messages have little impact, and sending notifications repeatedly results in a worse user experience.
Performance tuning best practices
Set the number of partitions for a topic reasonably
The following summarizes the dimensions recommended for tuning performance through partition, and recommends that you tune the overall performance of the system based on theoretical analysis and stress testing.
| Consider dimensions | illustrate |
| ------------------- | ---------- ||
| Throughput | Increasing the number of partitions can increase the concurrency of message consumption, and when the system bottleneck is on the consumer side, and the consumer side can scale horizontally, increasing the partition can increase the system throughput. In Kafka, each partition under each topic is an independent message processing channel, and messages in a partition can only be consumed by a consumer group at the same time, and when the number of consumer groups exceeds the number of partitions, the excess consumer group will be idle. |
| Message Order | Kafka can ensure the order of messages within a partition, and the message order between partitions cannot be guaranteed, so you need to consider the impact of message order on the business when increasing partition. |
| Instance Partition Cap | An increase in partition consumes more underlying memory, resources such as IO and file handles. When planning the number of partitions for a topic, you need to consider the upper limit of the partition that the Kafka cluster can support. |
A description of the relationship between producers, consumers and partitions.
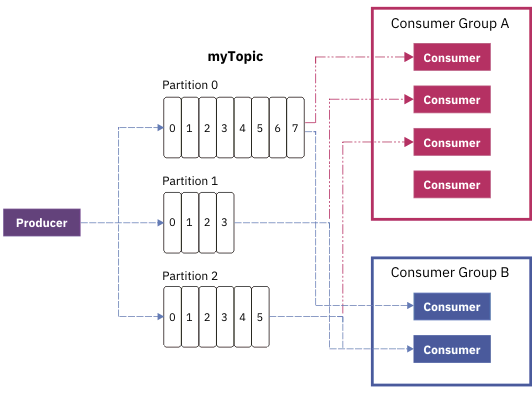
Set the batch size appropriately
If multiple partitions are set for a topic, producers need to confirm which partition to send messages to. When sending multiple messages to the same partition, the Producer client packages the relevant messages into a batch and sends them to the server in batches. In general, small batches cause a large number of requests from the Producer client, causing the request queue to be queued on the client and server side, which will push up the overall delay of message sending and consumption.
A suitable batch size can reduce the number of requests made by the client to the server when sending messages, and improve the throughput and latency of message sending overall.
The Batch parameters are described as follows:
| Parameter | Description |
|---|---|
batch.size |
The amount of message cache sent to each partition (the sum of bytes of message content, not the number of messages). When the set value is reached, a network request is triggered, and then the Producer client sends the message to the server in batches. |
linger.ms |
The maximum time that each message remains in the cache. If this time is exceeded, the Producer client ignores it batch.size , immediately send messages to the server. |
buffer.memory |
When the overall size of all cached messages exceeds this value, the message is triggered to be sent to the server, which is ignored batch.size and linger.ms Restrictions.buffer.memory The default value is 32MB, which guarantees sufficient performance for a single Producer. |
There is no universal method for selecting Batch-related parameter values, and we recommend that you perform stress test tuning for performance-sensitive business scenarios.
Use sticky partitioning to handle bulk sends
Kafka producers and servers have a batch sending mechanism when sending messages, and only messages sent to the same partition will be put into the same batch. In the scenario of sending large batches, if messages are scattered among multiple partitions, multiple small batches may be formed, causing the batch sending mechanism to fail and reduce performance.
Kafka’s default partition selection strategy is as follows
| Scenario | Policy |
|---|---|
| The message specifies Key | Hash the key of the message, and then select a partition based on the hash result to ensure that messages of the same key will be sent to the same partition. |
| The message does not specify Key | The default policy is to loop through all partitions of the topic, sending messages to each partition in a round-robin fashion. |
It can be seen from the default mechanism that the selection of partition is highly random, so it is recommended to set it in the scenario of mass transmission partitioner.classparameter that specifies the custom partition selection algorithm implementation Sticky partitioning。
One way to do this is to use the same partition for a fixed period of time and switch to the next partition after a period of time to avoid scattering data across multiple different partitions.
Common best practices
Kafka’s guarantee of message order
Kafka guarantees message order within the same partition, and cannot ensure global order if a topic has multiple partitions. If you need to guarantee the global order, you need to control the number of partitions to one.
Set a unique key for the message
Message Queuing Kafka messages have two fields: Key (message ID) and Value (message content). For easy tracking, it is recommended to set a unique key for the message. After that, you can use the key to track a message, print the sending log and consumption log, and understand the production and consumption of the message.
Set the retry policy of the queue reasonably
In a distributed environment, messages occasionally fail to be sent due to network and other reasons, perhaps because the message has been successfully sent but the ACK mechanism has failed, or the message has not been sent successfully. The default parameters can meet most scenarios, but you can set the following retry parameters as needed according to your business needs:
| parameter | illustrate |
|---|---|
retries |
Number of retries, the default value is 3, but consider setting it to apps with zero tolerance for data loss Integer.MAX_VALUE(valid and maximum). |
retry.backoff.ms |
The retry interval is recommended to be set to 1000. |
❗ Note:
If you want to implement At Most Once semantics, retries need to be turned off.
Access best practices
Spark Streaming accesses Kafka
Spark Streaming is an extension of Spark Core for high-throughput and fault-tolerant processing of persistent data, and currently supports external inputs such as Kafka, Flume, HDFS/S3, Kinesis, Twitter, and TCP sockets.

Spark Streaming abstracts continuous data into DStream (Discretized Stream), while DStream consists of a series of continuous RDDs (Elastic Distributed Datasets), each RDD is data generated within a certain time interval. Using functions to process DStream is essentially processing these RDDs.
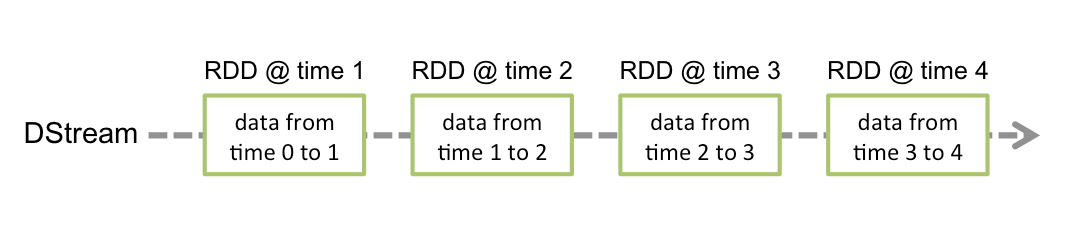
When using Spark Streaming as data input to Kafka, both stable and experimental versions of Kafka are supported:
| Kafka Version | spark-streaming-kafka-0.8 | spark-streaming-kafka-0.10 |
|---|---|---|
| Broker Version | 0.8.2.1 or higher | 0.10.0 or higher |
| Api Maturity | Deprecated | Stable |
| Language Support | Scala、Java、Python | Scala、Java |
| Receiver DStream | Yes | No |
| Direct DStream | Yes | Yes |
| SSL / TLS Support | No | Yes |
| Offset Commit Api | No | Yes |
| Dynamic Topic Subscription | No | Yes |
This exercise uses version 0.10.2.1 of Kafka dependencies.
Procedure
Step 1: Create a Kafka cluster and topic
The steps to create a Kafka cluster are slight, and then create a named one test of Topic.
Step 2: Prepare the server environment
Centos 6.8 system
| package | version |
|---|---|
| sbt | 0.13.16 |
| hadoop | 2.7.3 |
| spark | 2.1.0 |
| protobuf | 2.5.0 |
| ssh | CentOS is installed by default |
| Java | 1.8 |
The specific installation steps are omitted, including the following steps:
- Install SBT
- Install Protobuf
- Install Hadoop
- Install Spark
Step 3: Docking Kafka
Produce messages to Kafka
Here the 0.10.2.1 version of the Kafka dependency is used.
- at
build.sbtTo add a dependency:
1 | |
-
disposition
producer_example.scala:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19import java.util.Properties
import org.apache.kafka.clients.producer._
object ProducerExample extends App {
val props = new Properties()
props.put("bootstrap.servers", "172.0.0.1:9092") // 实例信息中的内网 IP 与端口
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer")
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer")
val producer = new KafkaProducer[String, String](props)
val TOPIC="test" // 指定要生产的 Topic
for(i<- 1 to 50){
val record = new ProducerRecord(TOPIC, "key", s"hello $i") // 生产 key 是 "key",value 是 hello i 的消息
producer.send(record)
}
val record = new ProducerRecord(TOPIC, "key", "the end "+new java.util.Date)
producer.send(record)
producer.close() // 最后要断开
}
For more information on how to use ProducerRecord, see ProducerRecord Documentation.
Consume messages from Kafka
####### DirectStream
- at
build.sbtTo add a dependency:
1 | |
- disposition
DirectStream_example.scala:
1 | |
####### RDD
- disposition
build.sbt(The configuration is the same as above,Click View)。 - disposition
RDD_example:
1 | |
more kafkaParams Usage reference kafkaParams Documentation.
Flume is connected to Kafka
Apache Flume is a distributed, reliable, and highly available log collection system that supports a variety of data sources (such as HTTP, Log files, JMS, listening port data, etc.), and can efficiently collect, aggregate, move, and store massive log data from these data sources into designated storage systems (such as Kafka, distributed file systems, Solr search servers, etc.).
The basic structure of Flume is as follows:
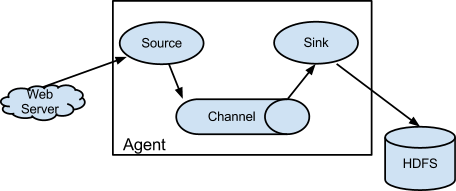
Flume has an agent as the smallest unit of independent operation. An agent is a JVM, and a single agent consists of three components: Source, Sink and Channel.
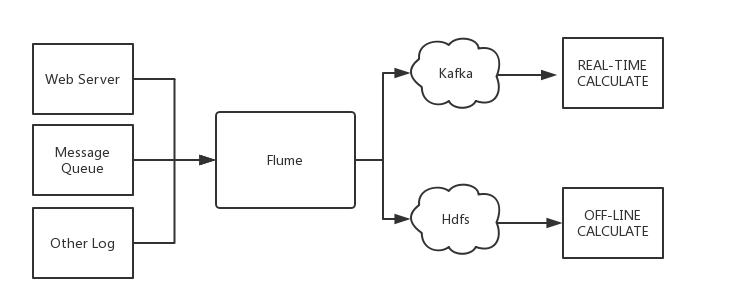
Flume and Kafka
When storing data to downstream storage modules or compute modules such as HDFS or HBase, you need to consider various complex scenarios, such as the amount of concurrent writes, system bearer pressure, and network latency. Flume is a flexible distributed system with multiple interfaces while providing customizable pipelines.
In the production processing stage, Kafka can act as a cache when production and processing speed are inconsistent. Kafka has a partition structure and appends data, which makes Kafka have excellent throughput capabilities; At the same time, it has a replication structure, which makes Kafka highly fault-tolerant.
So combining Flume and Kafka can meet most of the requirements in a production environment.
Preparations
- Download Apache Flume (Kafka compatible with version 1.6.0 or above)
- Download Kafka toolkit (Version 0.9.x or above, 0.8 is no longer supported)
- Confirm that Kafka’s Source and sink components are already in Flume.
Access method
Kafka can be used as a source or sink to import or export messages.
Kafka Source
Configure kafka as a source, that is, as a consumer, pulling data from Kafka into the specified sink. The main configuration options are as follows:
| Configuration Item | Description |
|---|---|
channels |
Self-configured Channel |
type |
Must be:org.apache.flume.source.kafka.KafkaSource |
kafka.bootstrap.servers |
Kafka Broker’s server address |
kafka.consumer.group.id |
Group ID |
kafka.topics |
Data source in Kafka Topic |
batchSize |
The size of each write to the Channel |
batchDurationMillis |
Maximum interval between writes |
Example:
1 | |
For more information, please refer to Apache Flume website。
Kafka Sink
Configure Kafka as a content receiver, that is, push yourself into the Kafka Server as a producer for subsequent operations. The main configuration options are as follows:
| Configuration Item | Description |
|---|---|
channel |
Self-configured Channel |
type |
Must be:org.apache.flume.sink.kafka.KafkaSink |
kafka.bootstrap.servers |
Kafka Broker’s server |
kafka.topics |
Data source in Kafka Topic |
kafka.flumeBatchSize |
Bacth size per write |
kafka.producer.acks |
Production strategy of Kafka producers |
Example:
1 | |
For more information, please refer to Apache Flume website。
Storm is connected to Kafka
Storm is a distributed real-time computing framework that can stream data and provide general-purpose distributed RPC calls, which can achieve sub-second latency in processing events, which is suitable for real-time data processing scenarios with high latency requirements.
How Storm works
There are two types of nodes in a Storm cluster, the control nodeMaster Nodeand worker nodesWorker Node。Master NodeonNimbusProcesses for resource allocation and status monitoring.Worker NodeonSupervisorprocess, listen for work tasks, startexecutorExecute. The entire Storm cluster dependszookeeperResponsible for public data storage, cluster status monitoring, task allocation and other functions.
The data handler that users submit to Storm is calledtopology, the smallest unit of message it processes istuple, an array of arbitrary objects.topologycomposedspoutandboltconstitutespoutis producedtupleThe source,boltYou can subscribe to anyspoutorboltIssuedtupleprocessing.

Storm with Kafka
Storm can use Kafka asspoutfor the processing of consumption data; Also asbolt, storing the processed data for consumption by other components.
Centos 6.8 system
| package | version |
|---|---|
| maven | 3.5.0 |
| storm | 2.1.0 |
| ssh | 5.3 |
| Java | 1.8 |
Prerequisites
- Download and install JDK 8. For more information, see Download JDK 8。
- Download and install Storm, reference Apache Storm downloads。
- A Kafka cluster is created.
Procedure
Step 1: Create a topic
Step 2: Add Maven dependencies
The pom.xml configuration is as follows:
1 | |
Step 3: Production Messages
Use spout/bolt
topology code:
1 | |
Create a spout class that generates messages sequentially:
1 | |
for tuple Add the two fields of key and message, when the key is null, the produced message is evenly distributed to each partition, and after specifying the key, it will be hashed to a specific partition according to the key value:
1 | |
Use trident
To generate topology using the trident class:
1 | |
Create a spout class that generates messages in bulk:
1 | |
Step 4: Consume messages
Use spout/bolt
1 | |
Use trident
1 | |
Step 5: Submit Storm
use mvn package After compilation, you can submit to the local cluster for debug testing, or you can submit to the production cluster for running.
1 | |
1 | |
Logstash accesses Kafka
Logstash is an open-source log processing tool that can collect data from multiple sources, filter the collected data, and store the data for other purposes.
Logstash is flexible, has powerful parsing capabilities, and is rich in plugins to support a variety of input and output sources. As a horizontally scalable data pipeline, Logstash works with Elasticsearch and Kibana to be powerful in log collection and retrieval.
How Logstash works
Logstash data processing can be divided into three stages: inputs → filters → outputs.
- Inputs: Generate data sources such as files, syslog, redis, and beats.
- filters: Modify the filtered data, which is an intermediate link in the Logstash data pipeline, and can change events according to conditions. Some common filters include: grok, mutate, drop, and clone.
- outputs: Transfer data elsewhere, an event can be transmitted to multiple outputs, and this event ends when the transfer is complete. Elasticsearch is the most common outputs.
At the same time, Logstash supports encoding and decoding, and the format can be specified on the inputs and outputs sides.
Logstash accesses Kafka’s advantages
- Data can be processed asynchronously: prevents bursts.
- Decoupling: When Elasticsearch is exceptional, upstream work is not affected.
❗ Note:
Logstash filtering consumes resources and affects its performance if deployed on a production server.
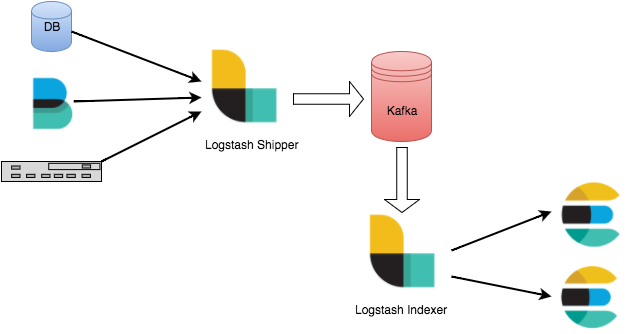
Procedure
Preparations
- Download and install Logstash, Reference Download Logstash。
- Download and install JDK 8, Reference Download JDK 8。
- A Kafka cluster is created.
Step 1: Create a topic
Create a file named logstash_testof Topic.
Step 2: Access Kafka
Access as inputs
-
execute
bin/logstash-plugin listto see if the supported plug-ins are includedlogstash-input-kafka。

-
at
.bin/directory to write a configuration fileinput.conf。
The standard output is used here as the data endpoint and Kafka as the data source.input { kafka { bootstrap_servers => "xx.xx.xx.xx:xxxx" // kafka 实例接入地址 group_id => "logstash_group" // kafka groupid 名称 topics => ["logstash_test"] // kafka topic 名称 consumer_threads => 3 // 消费线程数,一般与 kafka 分区数一致 auto_offset_reset => "earliest" } } output { stdout{codec=>rubydebug} } -
Run the following command to start logstash for message consumption:
./logstash -f input.confYou will see that the data in the topic just now is consumed.
Access as outputs
-
execute
bin/logstash-plugin listto see if the supported plug-ins are includedlogstash-output-kafka。
-
At.
bin/directory to write a configuration fileoutput.conf。
Standard inputs are used here as the data source and Kafka as the data destination.input { input { stdin{} } } output { kafka { bootstrap_servers => "xx.xx.xx.xx:xxxx" // ckafka 实例接入地址 topic_id => "logstash_test" // ckafka topic 名称 } } -
Run the following command to start Logstash and send a message to the created topic:
1
./logstash -f output.conf -
Start Kafka Consumer to verify the production data from the previous step.
1
./kafka-console-consumer.sh --bootstrap-server 172.0.0.1:9092 --topic logstash_test --from-begging --new-consumer
Filebeats access to Kafka
Beats platform A collection of single-purpose data collectors. Once installed, these collectors can be used as lightweight agents to send acquisition data from hundreds, thousands, or thousands of machines to targets.
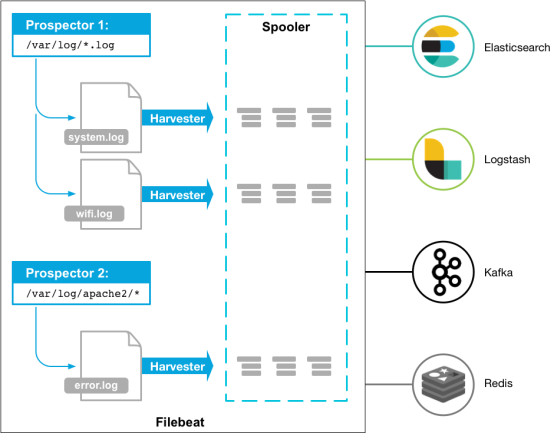
Beats has a variety of collectors that you can download to suit your needs. This topic uses Filebeat (Lightweight Log Collector) as an example to introduce the operation methods of Filebeat to access Kafka and solutions to common problems after access.
Prerequisites
- Download and install Filebeat (see Download Filebeat)
- Download and install JDK 8 (see Download JDK 8)
- A Kafka cluster has been created
Procedure
Step 1: Create a topic
Create a file named test of Topic.
Step 2: Prepare the configuration file
Go to the installation directory of Filebeat and create the configuration monitoring file filebeat.yml.
1 | |
Step 4: Filebeat sends the message
-
Run the following command to start the client:
1
sudo ./filebeat -e -c filebeat.yml -
Add data to the monitoring file (for example, a testlog file written to the listener).
1
2
3echo ckafka1 >> testlog
echo ckafka2 >> testlog
echo ckafka3 >> testlog -
Open the topic corresponding to Consumer consumption to obtain the following data.
1
2
3{"@timestamp":"2017-09-29T10:01:27.936Z","beat":{"hostname":"10.193.9.26","name":"10.193.9.26","version":"5.6.2"},"input_type":"log","message":"ckafka1","offset":500,"source":"/data/ryanyyang/hcmq/beats/filebeat-5.6.2-linux-x86_64/testlog","type":"log"}
{"@timestamp":"2017-09-29T10:01:30.936Z","beat":{"hostname":"10.193.9.26","name":"10.193.9.26","version":"5.6.2"},"input_type":"log","message":"ckafka2","offset":508,"source":"/data/ryanyyang/hcmq/beats/filebeat-5.6.2-linux-x86_64/testlog","type":"log"}
{"@timestamp":"2017-09-29T10:01:33.937Z","beat":{"hostname":"10.193.9.26","name":"10.193.9.26","version":"5.6.2"},"input_type":"log","message":"ckafka3","offset":516,"source":"/data/ryanyyang/hcmq/beats/filebeat-5.6.2-linux-x86_64/testlog","type":"log"}
SASL/PLAINTEXT mode
IF YOU NEED TO CONFIGURE SALS/PLAINTEXT, YOU NEED TO CONFIGURE A USER NAME AND PASSWORD. Add a new username and password configuration to the Kafka configuration area.
Reference link
Message Queuing CKafka - Documentation Center - Tencent Cloud (tencent.com)