Introduction to multi-copy erasure coding for distributed storage
This article was last updated on: February 7, 2024 pm
What is distributed storage?
Before we talk about multiple copies and erasure coding, let’s talk about distributed storage. Distributed storage is an architecture that differs from traditional centralized storage, often referred to as SDS or Software Defined Storage.
Traditional centralized storage adoptionController + HDD cabinetIn this way, data management and read and write capabilities are provided through redundant dual controllers (there are also multi-control storage of more than 2 controllers, mostly in high-end storage), and storage space is provided through the hard disk bay or expansion hard disk cabinet that comes with the controller, as shown below.
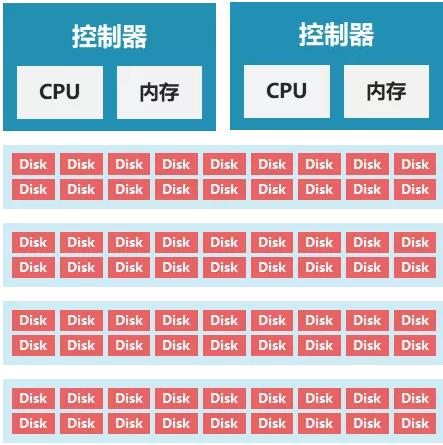
Centralized storage hard disk data protection mostly adopts RAID technology, such as RAID5, RAID6, RAID10, etc.
In order to achieve more flexible scalability and larger storage scale, distributed storage adopts a non-central networking mode, and each storage node can provide computing and storage resources at the same time。 They passInternal switchInterconnect, provide a unified pool of storage resources based on distributed storage software. For example, if 1 node is 200TB capacity, then 5 nodes are 1000TB capacity, and can be extended to thousands of nodes of exabyte-level capacity, so it is more suitable for scenarios with massive data.
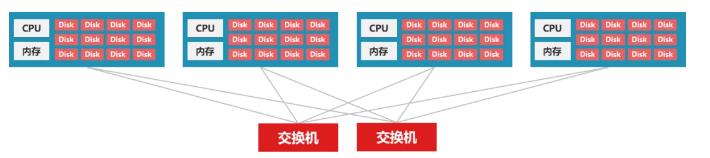
Unlike centralized storage, distributed storage uses hard disk data protectionMultiple copies and erasure codingTechnology.
What are multiple copies and erasure coding techniques?
Multiple copies, as the name implies, are multiple copies of data, simply put, multiple copies of a copy of data that are exactly the same, stored on multiple different nodes. For example, our commonly used 3 copies (as shown in the figure below) is to copy the data A in 3 copies, respectively stored on nodes 1, 3, 4, these three nodes are randomly selected in the entire cluster, the next B data may be placed on nodes 1, 2, 4.
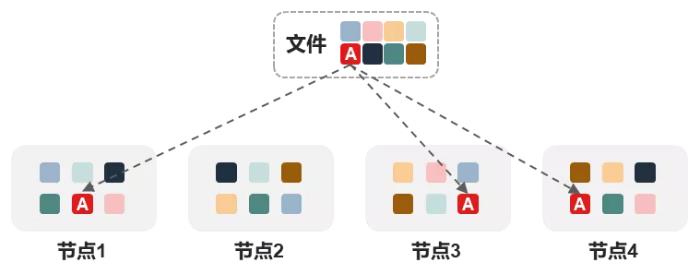
Looking at the data protection effect of multiple copies, it is clear that when nodes 1 and 3 fail at the same time, node 4 will still hold A data. By analogy, we can know that N-replica technology can allow N-1 nodes to fail data at the same time without loss. If it is a hard disk failure, as long as the range of the failed hard disk does not exceed N-1 nodes, the data will not be lost, for example, node 1 is broken with 3 disks, node 3 is broken with 4 disks, and the data will still not be lost.
Now that we understand what multiple copies are, let’s look at what erasure coding is. The full English name of erasure code is Erasure Code, so sometimes we also refer to it as EC. As the name suggests, erasure code is a checksum that corrects data loss, and you can compare it to a system of equations. If we know 4 numbers a, b, c, d, we can calculate 2 check data x and y through 2 different formulas, and save 6 data together, then when 1 or 2 of a, b, c, d are lost, we can reverse the lost 2 data through the remaining 2 values and calculation formulas. Like what:
Known:a+b+c+d=x=10,a+2b+3c+4d=y=20,c=2,d=1
So:a+b=7,a+2b=10,则 a=4,b=3
Of course, the above calculation is only a simplified scheme, the purpose is to help everyone understand that the verification method used in the real storage will be much more complicated than this, but the effect is similar.
If we use M+N to represent erasure coding, the above is a 4+2 erasure coding scheme, the data will be divided into 4 shards of the same size, and 2 check shards of the same size P and Q will be generated by the check algorithm. For example, 32KB data will be sliced into 4 8KB shards, and 2 8KB shards will be regenerated, for a total of 48KB data. When six data shards are generated, they are randomly stored on six different nodes (as shown in the figure below).
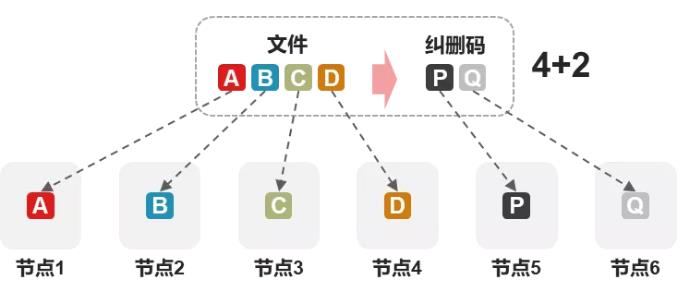
As with multiple copies, let’s look at the data protection effect of 4+2 erasure coding. As can be seen from the above figure, when any 2 nodes fail, the data will not be lost, because only 2 data shards will be lost, which can still be reversed. Of course, if 3 nodes fail at the same time, the erasure coding of 4+2 is powerless, just as 1 equation with 2 unknowns cannot be solved. Moreover, 4+2 erasure coding can also allow data failure in any number of hard disks in 2 nodes. For example, node 1 and node 2 fail 5 hard disks respectively, and it will not affect at all, because each group of 4+2 shards has 4 shards still in them, and the data is still reliable.
What are the storage node requirements for multiple copies and erasure coding?
Multiple copies and erasure coding have certain requirements for the number of nodes and hard disk configuration of distributed storage, mainly 2 points:
N replicas need at least N nodes to deploy, such as 3 replicas need at least 3 storage nodes, and M+N erasure coding requires at least (M+N) nodes, such as 4+2 erasure coding requires at least 6 nodes, of course, this is only the minimum requirement, the upper limit is not limited, and there will be no multiple ratio requirements, such as 3 replicas do not require 6, 9 nodes, 5, 7 nodes can also be;
The number of hard disks and the capacity per disk per node are the same, because if it is different, it will appearThe short board effect of the bucket, two nodes, one node configured with 8TB hard disk, one node configured with 4TB hard disk, 8TB hard disk can only be used as 4TB hard disk, because the data storage capacity of each node is randomly distributed and almost the same.
What is M+N:1 erasure coding?
In addition to the common M+N erasure coding, we often see an M+N:1 erasure code, which is a special erasure coding technique that we call itSubnode erasure coding。
The emergence of this technology is to meet the deployment requirements of small-scale clusters, for example, a user purchased 3 distributed storage nodes, because the number of nodes is relatively small, his optional data redundancy strategy is only 3 copies and 2+1 erasure coding (2 copies are not considered, we will explain the reasons in detail later). If you choose 3 copies, the space utilization rate of storage is only 33%, and if we consider other factors, such as the difference in the nominal value of the hard disk, system reserved space, and hot spare space, the free space may only be about 26%, which is more difficult for many users who value capacity. But if we choose 2+1 erasure coding, the problem arises, 2+1 erasure coding can only allow 1 shard data to be lost, and when 2 nodes in the cluster fail 1 hard disk, the data is lost!
In actual usage scenarios, although it is relatively rare for two hard disks to fail at the same time, the probability is not low, because many users may not notice the failure of one hard disk. During this time, storage is running in an extremely dangerous state, and any hard disk failure will lead to cluster data loss, obviously,The 2+1 erasure coding scheme is not good。
For these reasons, 4+2:1 erasure coding appears. Why is it called sub-node erasure coding, because the default erasure coding distributes data by node, but 4+2:1 willFollow the hard diskTo distribute data, it treats 3 nodes as 6 nodes, each node selects 2 hard disks, and the entire cluster selects 6 different hard disks to store 4+2 for a total of 6 shards of data (as shown in the figure below).
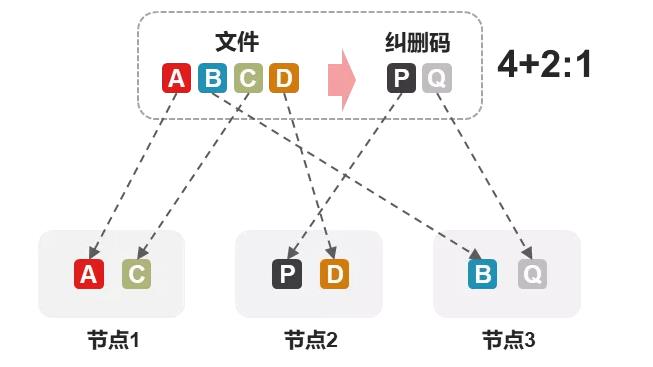
We see that compared with 2+1 erasure coding, although the number of tolerant node failures is still 1, 4+2:1 can allow 2 nodes to fail 1 hard disk respectively (a total of 2 failed hard disks) without data loss. In practice, the probability of hard disk failure is much lower than that of the entire node, so 4+2:1 is still very reliable, and its space utilization is much higher than that of 3 copies. Of course, if you are worried about the simultaneous failure of 2 nodes, then you can only choose 3 replicas.
Similar to 4+2:1, there are also sub-node erasure codes such as 8+2:1, 16+2:1, etc., which we will not discuss much here.
Which is better, multiple copies or erasure coding, and how should I choose?
When comparing multiple copies and erasure coding techniques, we can start with Available capacity, read and write performance, refactoring performance, reliabilityand other aspects of the analysis, as shown in the following table.
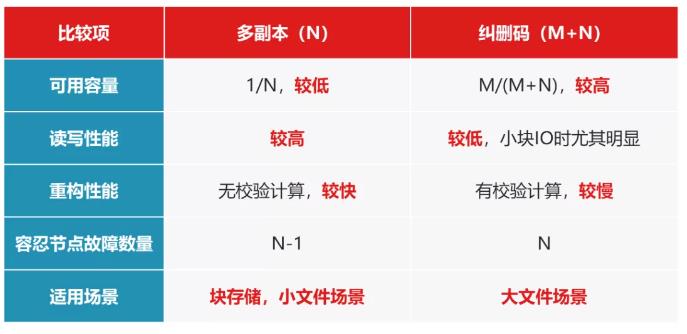
In terms of usable capacity, the advantages of erasure coding are large, such as The utilization rate of 4+2 erasure coding is 66%, but 3 copies are only 33%, the difference between the two is 2 times, 8+2 erasure coding can do 80%, this game erasure code wins!
In terms of read and write performance, multiple copies tend to be higher because of erasure codingData validation is involved at write time, and may produceWrite punishment,When reading, it spans multiple nodes。 For example, when 4+2 erasure coding reads 1 data, it needs to read 4 shards from 4 nodes and then stitch, and any 1 node delay is too high, which will have a great impact on performance. Multi-replica only needs to read 1 complete shard, and does not involve data stitching of nodes. The performance difference between the two will be more obvious when the IO block is small, but if the IO block is large,For example, 1MB, then the performance gap between the two will gradually narrow, because at this time there is less writing penalty, and erasure coding can also play well the advantages of multiple node concurrency, and this game of multiple copies is slightly better!
In terms of refactoring performance, multiple replicas also have a clear advantage, becauseIt does not involve data verification, just a simple copy of data, so the speed is relatively fast. The reconstruction of the erasure code involves the calculation process of reverse verification, and the amount of read and write data required and the CPU computing consumption will be greater, and this game of multiple copies is also slightly better!
i️Illustrate:
Reconfiguration refers to the data recovery process after the failure of the storage hard disk, restoring the data of the failed hard disk to the normal hard disk to ensure the integrity of the data.
In terms of reliability, the degree of fault redundancy of multiple replicas and erasure coding is often not much different, for example, 3 replicas and 4+2 erasure coding can allow any 2 nodes to fail without data loss. But we also need to pay attention to two points:
- Multi-copy refactoring performance tends to be faster than erasure coding, so hard disk failure recovery is also faster, which will bring someAdvantages in reliability。
- Erasure coding can use +3, +4 strategies to tolerate more node failures, and the space utilization is not too low, but if multiple replicas use 4 replicas, 5 replicas are too expensive, so erasure coding has advantages at this point.
This game is indistinguishable!
On the whole,If users are more concerned about performance, especially in small IO scenarios, multiple copies are often a better choice, and if users are more concerned about usable capacity and large file scenarios, erasure coding will be more suitable。
What specifications should I choose for erasure coding and multiple copies?
Common multi-copy and erasure coding strategies are as follows, which we analyze one by one:
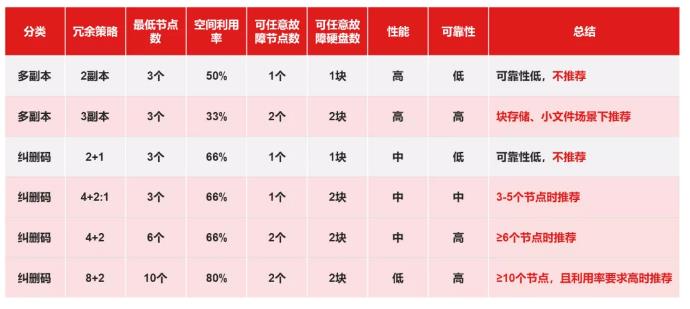
2 copies:
Not recommended! Not recommended! Not recommended!Say important things 3 times because it’s really dangerous! Many users may value 2 copies of good space utilization (50%), and the performance is also very good, but the bottom line of choosing storage is often the reliability of data, and you must not lose the big because of the small. 2 Replicas can only tolerate any 1 drive failure, once 1 drive fails, the entire cluster is in a precarious state, and any problems can result in the loss of all data. And think of hard drivesAverage failure rate of 1%-2% per year, the entire cluster may have hundreds of hard disks, do you want to be afraid several times a year? So in addition to dev test scenarios and not worrying about data loss at all, forget about 2 copies, it’s really dangerous!
3 copies:
If you’re going to choose multiple replicas, then 2 replicas are too dangerous and 4 replicas are too space-consuming, so 3 copies are the best option。 It has no other disadvantages except for a little lower space utilization, and the cost is actually acceptable when the capacity requirements are not high.This solution is recommended for block storage and small file scenarios。
2+1 erasure code:
equallyNot recommended, the reason is the same as 2 copies, too dangerous, and there is 4+2:1 erasure coding, which is a better scheme than it everywhere, why look at 2+1 erasure coding more.
4+2:1 erasure code:
When the number of cluster nodes is less than 6 and 4+2 cannot be used, 4+2:1 subnode erasure coding is undoubtedly the best choice, which allows any 2 hard disks to fail without losing data, and the space utilization is exactly the same as 2+1.
4+2 erasure code:
When the number of cluster nodes is ≥ 6, 4+2 erasure coding is a good choice, because it can tolerate the hard disk failure data of any 2 nodes without loss, and the space utilization is also high (66%).
8+2 erasure code:
When the number of cluster nodes is ≥ 10 and space utilization is more important than performance, 8+2 erasure coding is also an option, which has a space utilization of up to 80%, but note that performance may not be ideal.
Sum upWhen you select multiple replicas, 3 replicas is almost the only option, when you choose erasure coding, you can choose according to the number of nodes in the cluster, choose 4+2:1 when 3-5 nodes, choose 4+2 when ≥ 6 nodes, if you pay more attention to space utilization and do not require high performance, you can also consider 8+2 erasure coding.
In addition, some people may ask, can 5+2, 8+3, 16+2 and other erasure codes be used? In fact, because of the characteristics of computer binary,M of M+N erasure code We tend to take the power of 2, such as 2, 4, 8, 16, so that the efficiency of slicing is higher, so erasure codes such as 5+2 are rarely used. Although 8+3, 8+4 erasure codes are more reliable than +2, they are rarely used because the probability of failing 3 or 4 nodes at the same time is too low, and the resulting performance degradation is not cost-effective. The advantage of 16+2 is that the space utilization rate is relatively high (89%), but the performance is also low, so if the user’s cluster size is relatively large, the space utilization requirements are extremely high, and a certain performance degradation can be tolerated, 16+2 or 16+2:1 will also be used in a few scenarios.
The above is a summary of the multiple copies and erasure coding technology in distributed storage, I hope it will be helpful to you.