Reading Notes - Large-scale Distributed Storage Systems: Principle Analysis and Architecture Practice: V
This article was last updated on: February 7, 2024 pm
5 Distributed key-value system
It can be seen as a special case of the distributed tabular model.
Hash distribution algorithm.
5.1 Amazon Dynamo
| Question | Techniques taken |
|---|---|
| Data Distribution | Improved consistent hashing (virtual nodes) |
| Copy Protocol | Replicated-write Protocol (NWR parameter adjustable) |
| Data Conflict Handling | Vector clock |
| Temporary Troubleshooting | Data Backhaul (Hinted Handoff) |
| Recovery after a permanent failure | Merkle hash tree |
| Membership and error detection | Gossip-based membership and error detection protocol |
5.1.1 Data Distribution
The idea of a consistent hash algorithm: assign a random token to each node in the system, and these tokens form a hash ring. When performing a data placement operation, the hash value of the primary key is calculated first, and then stored in the clockwise direction of the node where the first token greater than or equal to the hash value is located.
Advantages of consistent hashing: When nodes are joined and deleted, only neighboring nodes in the hash ring are affected, and other nodes are not affected.
Dynamo uses an improved consistent hashing algorithm: each physical node is assigned multiple tokens based on its performance differences, one for each “virtual node”. The processing power of each virtual node is basically comparable and randomly distributed in the hash space.
Due to the existence of seed nodes, it is relatively simple to join new nodes. The new node first exchanges cluster information with the seed node and thus learns about the cluster. Other nodes in the DHT (Distributed Hash Table) ring also periodically exchange cluster information with seed nodes to discover new nodes joining.
5.1.2 Consistency and Replication
Replication: Data callback.
Dynamo highlight technology: NWR, N represents the number of backups replicated, R refers to the minimum number of nodes for successful read operations, and W refers to the minimum number of nodes for successful write operations. As long as W + R > N is satisfied, it is guaranteed that at least one valid data can be read when there is no more than one machine failure.
If the application attaches importance to read efficiency, you can set W = N, R=1, and if the application needs to make trade-offs between reading and writing, you can generally set N=3, W=2, and R=2.
NWR looks perfect, but it’s not. In a P2P cluster such as Dynamo, due to the different cluster information stored by each node, the same record may be updated by multiple nodes at the same time, and the update order between multiple nodes cannot be guaranteed. To this end, Dynamo introduced the technical means of Vector Clock in an attempt to resolve conflicts.
5.1.3 Fault Tolerance
Dynamo divides exceptions into 2 types:
- Temporary abnormalities: such as suspended animation
- Permanent abnormalities: such as hard disk repair or machine scrapping
Fault tolerance mechanism:
- Data callback
- Merkle tree synchronization
- Read repair
5.1.4 Load balancing
It depends on how each machine is assigned a virtual node number, or token.
How to assign nodes:
- Random allocation: The disadvantage is poor controllability.
- Data range allocation + random allocation
5.1.5 Read and Write Process

During the reading process, if the data is inconsistent, the default policy is to select the latest data based on the modification timestamp, of course, the user can also customize the conflict handling method. If the data version on some replicas is found to be too old during the read process, Dynamo will internally initiate a read repair operation asynchronously to fix the erroneous copy using the result of conflict resolution.

5.1.6 Stand-alone implementation
Dynamo’s storage nodes consist of 3 components:
- Request coordination
- Member and failure detection
- Storage engine
Dynamo is designed to support pluggable storage engines such as Berkerly DB, MySQL InnoDB, etc.
5.1.7 Discussion
Dynamo uses a P2P design without a central node, which increases the scalability of the system.
Dynamo only guarantees eventual consistency, and it is difficult to predict the outcome of the operation when multiple clients operate concurrently, and it is difficult to predict the inconsistent time window.
Overall, Dynamo has limited use cases on Amazon, and subsequent similar systems will adopt other design ideas to provide better consistency.
5.2 Taobao Tair
Tair is a distributed K/V storage engine developed by Taobao. Tair is used in two ways: persistent and non-persistent:
- Non-persistence can be thought of as a distributed cache
- Persisted Tair holds data on disk.
The number of backups of Tair configurable data.
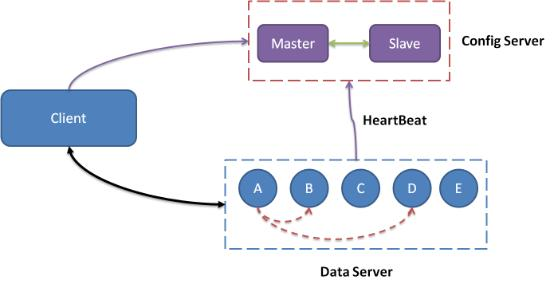
5.2.1 System Architecture
Compose:
- 1 central control node - config server: responsible for managing all data servers and maintaining their state information. One master and one reserve.
- Several service nodes - data server: various external data services and report their situation to Config Server in the form of a heartbeat.
5.2.2. Key Issues
Data distribution
Once hashed, distributed into Q buckets. Q is much larger than the number of physical machines in the cluster, such as Q = 10240
fault tolerance
Data migration
config server
The client caches the routing table.
Data Server
Data Server has an abstract storage engine layer that makes it easy to add new storage engines. Data Server also has a plugin container that dynamically loads and unloads plugins.
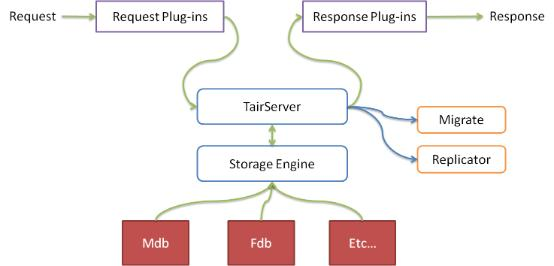
By default, there are two storage engines:
- Mdb
- Fdb
5.2.3 Discussion
The central node, Config Server, was introduced in Tair. This makes it easy to handle data consistency and eliminates the need for complex P2P techniques such as vector clocks, data backhaul, Merkle numbers, and collision handling. In addition, the load on the central node is low.
Tair persistence is not as good as it should be. For example, Tair persistent storage passesAsynchronous replicationTechnology improves reliability and may lose data.