K3S Series Articles - 5G IoT Gateway Device POD Access Error DNS 'I/O Timeout' Analysis and Resolution
This article was last updated on: February 7, 2024 pm
Opening
Overview of the problem
20220606 5G IoT gateway device installs K3S Server at the same time, but the POD cannot access the Internet address, check the CoreDNS log as follows:
1 | |
That is, the DNS query forwards to the 8.8.8.8 DNS server, and the query times out.
As a result, PODs that require network startup cannot start normally, and frequent CrashLoopBackoff, as shown below:
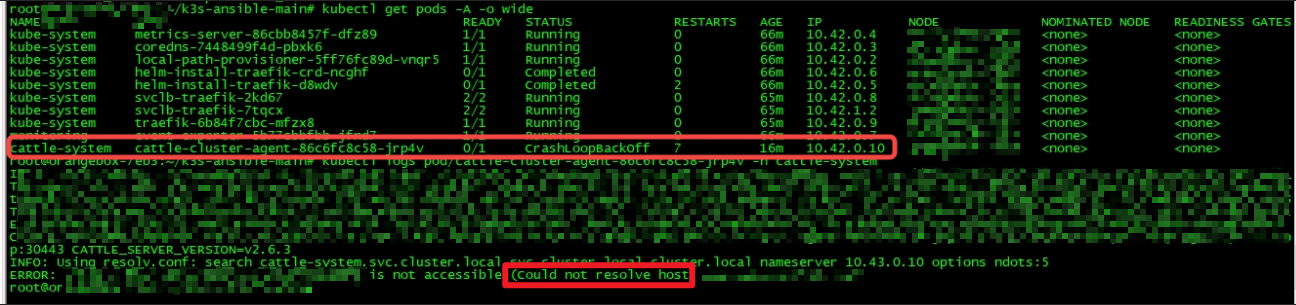
However, direct access through Node can be accessed normally, as shown below:

Environmental information
- Hardware: 5G IoT gateway
- Internet:
- Internet access: 5G network card: is a USB network card, needs to be started through the dialer, the program will call the system’s dhcp/dnsmasq/resolvconf, etc
- Intranet access: WLAN network card
- Software: K3S Server v1.21.7+k3s1, dnsmasq, etc
analyse
Network detailed configuration information
Check the analysis step by step:
- see
/etc/resolv.conf, the discovery configuration is 127.0.0.1 - netstat sees that local port 53 is indeed running
- This is usually the case when a DNS server or cache is started locally to see if the dnsmasq process exists, and it does exist
- The resolv.conf configuration for dnsmasq is
/run/dnsmasq/resolv.conf
1 | |
CoreDNS analysis
It’s strange here, but I didn’t find where DNS 8.8.8.8 is configured, but the log shows that it points to this DNS:
1 | |
Let’s take a look at the configuration of CoreDNS: (K3S’s CoreDNS is initiated via manifests at:/var/lib/rancher/k3s/server/manifests/coredns.yaml Down)
1 | |
There are 2 main configurations to focus on here:
forward . /etc/resolv.confloop
Common analysis process for CoreDNS issues
Check if the DNS pod is working properly - Result: Yes;
1 | |
Check that the DNS service has the correct cluster-ip - Result: Yes:
1 | |
Check whether the domain name can be resolved:
First internal domain name - Result: Unable to resolve:
1 | |
Retry the external domain name - Result: Unable to resolve:
1 | |
Check the nameserver configuration in resolv.conf - result: 8.8.8.8 indeed
1 | |
In summary:
It should be inside the POD /etc/resolv.conf is configured to nameserver 8.8.8.8 This caused this problem.
But the entire Node OS level is not configured nameserver 8.8.8.8So the suspicion is: Kubernetes, Kubelet, CoreDNS, or CRI level has such a mechanism to automatically configure DNS when it is abnormal nameserver 8.8.8.8。
So, to solve the problem, it is still necessary to find the DNS configuration exception.
Container network DNS service
I haven’t found specific evidence of DNS related to Kubernetes, Kubelet, CoreDNS, or CRI here, and the CRI for K3S is containerd, but I’m here The official documentation for Docker Saw a description like this:
📚️ Reference:
If the container cannot reach any of the IP addresses you specify, Google’s public DNS server 8.8.8.8 is added, so that your container can resolve internet domains.
If the container can’t reach any of the (DNS) IP addresses you specify, add Google’s public DNS server 8.8.8.8 so that your container can resolve the internet domain.
Here’s speculation that Kubernetes, Kubelet, CoreDNS, or CRI may have a similar mechanism.
From here analysis, we can know that the root cause is still a DNS configuration problem, and the CoreDNS configuration is the default, so the biggest possibility is /etc/resolv.conf configured as nameserver 127.0.0.1 caused this problem.
Root cause analysis
Root cause: /etc/resolv.conf configured as nameserver 127.0.0.1 caused this problem.
The official documentation for CoreDNS makes this clear:
📚️ Reference:
loop | CoreDNS Docs
When the CoreDNS log contains messagesLoop ... detected ..., this means detecting the plug-inloopAn infinite forwarding loop was detected in one of the upstream DNS servers. This is a fatal error because operating with an infinite loop will consume memory and CPU until the host eventually dies out of memory.
Forwarding loops are typically caused by the following:
Most commonly, CoreDNS forwards requests directly to itself. For example, pass127.0.0.1、::1or127.0.0.53Equal loopback address
To resolve this issue, review any forwarding in the region in the Corefile where the loop is detected. Make sure they are not forwarded to a local address or to another DNS server, which is forwarding the request back to CoreDNS. If forward is using a file (for example, /etc/resolv.conf), make sure that the file does not contain a local address.
As you can see here, our CoreDNS configuration contains:forward . /etc/resolv.conf, and on Node /etc/resolv.conf fornameserver 127.0.0.1. And the ones mentioned aboveInfinite forwarding loop target Fatal error Matching.
Forwarding loops are typically caused by the following:
Most commonly, CoreDNS forwards requests directly to itself. For example, through a loopback address, such as , or 127.0.0.1::1127.0.0.53
Workaround
📚️ Reference:
loop | CoreDNS Docs
There are 3 official solutions:
- kubelet added
--resolv-confDirectly to the “real”resolv.conf, Generally:/run/systemd/resolve/resolv.conf- Disable local DNS caching on the Node
- Quick dirty method: modify the Corefile, put
forward . /etc/resolv.confto be replaced withforward . 8.8.8.8and so on for DNS addresses that can be accessed
In view of the above methods, we analyze them one by one:
- ✔️ Feasible: kubelet added
--resolv-confDirectly to the “real”resolv.conf: As mentioned above, our “real”resolv.confFor:/run/dnsmasq/resolv.conf - ❌ Not feasible: Disable local DNS caching on Node, as this is a special case based on 5G IoT gateways, which is the case with the 5G gateway program mechanism, which uses dnsmasq
- ❌ Not feasible: dirty method, and the DNS obtained by the 5G gateway is not fixed and changes at any time, so we can’t specify it
forward . < 固定的 DNS 地址 >
In summary, the solution is as follows:
Add the following fields to the K3S service:--resolv-conf /run/dnsmasq/resolv.conf
After adding, it is as follows:
1 | |
Then execute the following commands reload and restart:
1 | |
to return to normal.
If it needs to be resolved at installation time, the workaround is as follows:
- Using the k3s-ansible script, group_vars additionally add the following
--resolv-confParameter:extra_server_args: '--resolv-conf /run/dnsmasq/resolv.conf' - Use the official k3s script: Reference K3s Server Configuration Reference | Rancher documentation, add parameters:
--resolv-conf /run/dnsmasq/resolv.confOr use environment variables:K3S_RESOLV_CONF=/run/dnsmasq/resolv.conf
🎉🎉🎉